Immer mehr Unternehmen zerschlagen ihre Software-Systeme in kleine Microservices. Wenn das passiert, entstehen mehrere Deployment-Artefakte, was nicht nur das Deployment des Gesamtsystems komplexer macht. Um diese Komplexität beherrschen zu können und die Auslieferungsmöglichkeiten einer Software zu verbessern, ist der Einsatz von Werkzeugen zur Infrastruktur-Automatisierung unumgänglich.
Microservices and Conversion Hunting: Build Architectures for Changeability
To gain validated learning and reduce risk and uncertainty while developing new products, you have to bring each increment into production. Only information gathered from the behavior of real users with each increment ensures that you’ll build the right thing in the end. In this session, you’ll learn how you can stop building monolithic systems and start designing software based on microservices—each having its own lifecycle and being an independent deployment unit. You’ll get a pretty good idea of how to manage such distributed applications in production successfully as well. The presentation uses an online shop application based on microservices for a discussion of topics such as deployment and operational aspects such as monitoring and logging.
https://www.youtube.com/watch?v=DYX64Thqu8M
Folien:
slides/14_javaone/
Quellcode:
https://github.com/zutherb/AppStash/
Microservice – Deployment ganz einfach
Um veränderbare Software zu erhalten, die in kurzen Zyklen ausgeliefert werden kann, zerlegen immer mehr Unternehmen ihre Software-Systeme in kleine Microservices. Hat man seine Software in Microservices zerlegt, erhält man mehrere Deployment-Artefakte, was das Deployment des Gesamtsystems aber auch komplexer macht. Um diese Komplexität beherrschen zu können, ist der Einsatz von Werkzeugen zur Infrastrukturautomatisierung unumgänglich.
Wir schauen uns deshalb an einem Microservice-Architektur-Beispiel an, wie man Deployment-Pipelines mit verschiedenen auf Docker basierenden Werkzeugen, wie z.B. Kubernetes und Vamp, aufbauen und ein verteiltes System hochverfügbar und stressfrei betreiben kann.
Folien:
slides/11_ljugm/
Quellcode:
https://github.com/zutherb/AppStash/
Java aktuell – Bernd Zuther – Microservices und die Jagd nach mehr Konversion – das Heilmittel für erkrankte It-Architekturen
Die Software-Entwicklung begibt sich derzeit auf eine neue Evolutionsstufe: Fachabteilungen haben gelernt, mithilfe agiler Methoden Änderungen in kurzen Zyklen produktiv umzusetzen. Damit haben sie die Möglichkeit, Änderungen an einem Produkt mit echtem Benutzer-Feedback vermessen zu können und durch empirische Untersuchungen des Benutzerverhaltens fundierte Entscheidungen über neue Software-Funktionalitäten zu treffen. Dazu müssen aber die meisten IT-Architekturen erst einmal so auf Vordermann gebracht werden, dass einzelne Teile einer Software flexibel ausgetauscht und unabhängig voneinander ausgeliefert werden können.
Microservices und die Jagd nach mehr Konversion – Fluch oder Segen für den Entwickler
Softwareentwicklung wandelt sich derzeit: Es reicht nicht mehr Produktinkremente potenziell produktiv zu setzen, sondern Änderungen müssen produktiv gehen. Um in gesättigten Märkten noch Innovationen hervorzubringen und neues Wachstum zu generieren, arbeiten Fachabteilungen immer öfter mit Lean-Startup-Methoden. Eine Methode im Lean-Startup ist die Bildung von Hypothesen, die durch Tests validiert werden. Dazu wird Software in unterschiedlichen Varianten ausgespielt und dann beobachtet, wie Kunden auf eine Änderungen reagieren. Je nach Test-Ergebnis werden Teile der Software dann wieder entfernt oder angepasst. Somit ist es wichtig Software schnell an den an den Anwender zu bringen.
Software schneller in Produktion zu bringen, ist mit den meisten Softwarearchitekturen nicht so einfach. Häufig existieren monolithische Anwendungen, die kompliziert zu installieren sind und bei denen für kleine Änderungen die Koordination von vielen Teams nötig ist. Um Teile der Software zu entkoppeln und Koordinationsaufwand zwischen den Teams zu verringern, wird häufig vorgeschlagen eine Applikation in kleine Dienste zu zerlegen, oft kurz Microservice-Architektur genannt.
Wir sehen uns an Hand eines konkreten Beispiels an, wie man eine bestehende Architektur in eine Mircroservice-Architektur überführen kann und welche Konsequenzen dies auf technischer Ebene hat. Zum Beispiel führen Microservices zu mehreren Deployment Pipelines und man braucht Konzepte die unterschiedlichen Teile der Software auch schnell auf unterschiedlichen Rechner provisionieren zu können. Außerdem sollte man sich Gedanken zum Thema Logging und dem Monitoring im Betrieb machen, denn sonst kann der Betrieb eines solchen hochverteilten Systems schnell zur Qual werden.
Folien
- slides/zuther/slides/02_bobkonf/index.html
- Quellcode
- https://github.com/zutherb/AppStash/
- Artikel in der Java-Aktuell 02/2015
Deployment ganz einfach – Microservice Deployment mit Hilfe der Linux Paketverwaltung
Softwareentwicklung wandelt sich, anstatt Software für die nächsten Jahre zu planen, zu entwickeln und dann erst dem Kunden zu präsentieren, arbeiten Fachabteilungen oft mit kleinen Hypothesen. Diese Hypothesen werden mithilfe von A/B Tests direkt am Kunden validiert und kommen dann als neue Userstories in den Entwicklungsprozess. Damit werden schrittweise Unternehmensprozesse und bestehende Software optimiert. Durch dieses Vorgehen bauen Fachabteilung Software, die ihre Kunden wirklich wollen. Das stellt die IT-Abteilungen natürlich vor die Herausforderung öfter und schneller ausliefern zu müssen, um schneller von den Testergebnissen profitieren zu können und letztlich mehr Umsatz zu generieren.
Beispielsweise kann eine simple Änderung der Farbe eines Links in einem Online-Shop eine Konvertierungssteigerung von 20% auslösen. Ein solche Änderung ist relativ schnell umgesetzt, doch selbst mit Continuous Delivery und einer Deployment Pipeline kann, der Durchlauf bis in Produktion mehrere Stunden in Anspruch nehmen, was ziemlich viel Geld kosten kann. Es gibt deshalb Stimmen, die meinen, dass solche langen Durchlaufzeiten am architektonischen Aufbau der Anwendungen liegt.
Aufbau von Web-Anwendungen
Web-Anwendungen sind häufig aus den folgenden drei Teilen aufgebaut:
- Einer Benutzerschnittstelle (z.B. HTML),
- einer Datenbank und
- einer Server-Komponente.
Die Server-Komponente kümmert sich um die Abarbeitung der HTTP Requests, führt die Domänenlogik aus, ließt und schreibt Daten aus/in die Datenbank, bestimmt welche Teile der Benutzerschnittstelle ausgeliefert werden müssen. Jede Änderung in diesem System erfordert einen Build und ein Deployment einer neuen Version der kompletten Software. Solche Anwendungen werden auch Monolithen genannt.
Auch wenn Monolithen sehr erfolgreich sein können, gibt es eine steigende Anzahl von Leuten, die mit diesen Ansatz nicht zufrieden sind, weil man auch für kleine Änderungen sehr hohe Durchlaufzeiten bis in Produktion hat und die Entwicklungsteams nicht mehr richtig skalieren, da man immer wieder die komplexen und zeitaufwendigen Buildprozesse der Monolithen durchlaufen muss und Änderungen an der Software immer schwieriger werden. Außerdem skalieren Monolithen schlecht. Wenn man einen solchen Monolithen skalieren möchte, muss man immer die komplette Anwendung verteilen, auch wenn nur bestimmte Teile der Anwendung Performance-Probleme hervorrufen.
Es gibt Stimmen, die meinen, dass die klassische Drei-Schichten nicht mehr gut genug skaliert, um kleine gewinnbringende Features schnell genug ausliefern zu können. Deshalb erfreut sich das Konzept der Microservice-Architektur immer größer Beliebtheit. Ziel ist es die Anwendung entsprechend ihrer Fachlichkeit zuzuschneiden und in kleine Services zu unterteilen, die getrennt von einander ausgeliefert werden können. Damit soll die Durchlauf eines Features bis in Produktion verringert werden.
Die Microservice-Architektur zerschneidet Anwendungen in eine Anzahl an Diensten. Diese Dienste sind eigenständig deploy- und skalierbar. Jeder Dienst stell eine abgrenzte Fachlichkeit bereit, kann in einer beliebigen Programmiersprache implementiert sein und von unterschiedlichen Teams bereitgestellt werden. Zerschneidet man eine Software in eigenständige Dienste erzeugt man natürlich eine Vielzahl an Deployment-Artifakten. Häufig hat der Betrieb aber schon Probleme mit dem Deployment einer einzelnen monolithischen Anwendung. Deshalb muss man einen Weg finden Abhängigkeiten besser aufzulösen, die für eine erfolgreiche Auslieferung benötigt werden.
Deployment von Web-Anwendungen
In der Regel werden Web-Anwendungen in einen Anwendungsserver aufgeliefert. Ein Anwendungsserver stellt einen Container dar, der spezielle Dienste zur Verfügung stellt, wie beispielsweise Transaktionen, Authentifizierung oder den Zugriff auf Verzeichnisdienste, Webservices und Datenbanken über definierte Schnittstellen.
Um das Deployment in einem Anwendungsserver zu standardisieren gibt es das Web Archive oder das Enterprise Archive. Ein Web Archive ist ein Dateiformat, das beschreibt, wie eine vollständige Webanwendung nach der Java-Servlet-Spezifikation in eine Datei im JAR- bzw. ZIP-Format verpackt wird. Bei einem Enterprise Archive handelt es sich ebenfalls um eine Datei im JAR- bzw. ZIP-Format, die ein vollständiges Anwendungsprogramm – meist eine Webanwendung – gemäß dem Standard Java Platform, Enterprise Edition (Java EE) enthält. Leider reichen diese beiden Standards nicht aus, um alle Abhängigkeiten aufzulösen, die eine Anwendung für den fehlerfreien Betrieb benötigen.
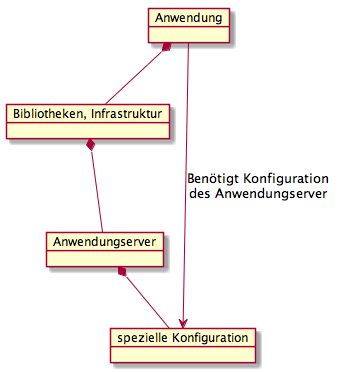
Die Abbildung zeigt die Abhängigkeiten zwischen Anwendung und Anwendungsserver. Eine Anwendung hängt vom Anwendungsserver ab, da die Anwendung Bibliotheken und Infrastruktur des Anwendungsserver nutzt. Umgekehrt ist der Anwendungsserver aber auch von der Anwendung abhängig, da der Anwendungsserver für eine Anwendung speziell konfiguriert werden muss. Damit ist ein Anwendungsserver eigentlich Teil einer Anwendung und man sollte Anwendungsserver und Anwendung als eine Komponente sehen.
Benötigt eine neue Version der Anwendung auch einen neue Version des Anwendungsserver gibt es für den Betrieb häufig viele manuelle Schritte auszuführen, weil diese Abhängigkeiten in eine WAR oder einem EAR nicht ausgedrückt werden können. Diese Abhängigkeiten werden dann oft textuell in Form eines Tickets beschrieben und wenn man Glück hat werden die Instruktionen vom Betrieb richtig ausgeführt. Ähnliches gilt bei Datenbankänderungen. Es wäre deshalb wünschenswert Deployment-Artifakte zu haben, die auch diese Abhängigkeiten ausdrücken können. Ein Beispiel für solche Deployment-Artifakte liefert Apple.
Deployment von Anwendungen über den App Store
 Apple liefert pro Sekunde mehr als 800 Apps über den App Store aus (Quelle). Apple-typisch lädt man sich eine Anwendung herunter und nach einem Klick auf das Icon läuft die Anwendung immer sofort, ohne das der Benutzer noch irgend etwas machen muss.
Apple liefert pro Sekunde mehr als 800 Apps über den App Store aus (Quelle). Apple-typisch lädt man sich eine Anwendung herunter und nach einem Klick auf das Icon läuft die Anwendung immer sofort, ohne das der Benutzer noch irgend etwas machen muss.
Apple löst die Herausforderung eine Anwendung auszuliefern mit dem sogenannten Application Bundle. Native Mac OS X Applikationen sind mehr als nur eine einfache ausführbare Datei, auch wenn ein Benutzer im Finder immer nur ein einzelnes Ic on sieht. Unter Mac OS X besteht eine Applikation Bundle aus einer Verzeichnisstruktur, die sowohl die ausführbaren Dateien als auch alle benötigen Ressourcen enthält, die von einer Applikation benötigt werden. Diese Struktur ist von Apple genau definiert.
on sieht. Unter Mac OS X besteht eine Applikation Bundle aus einer Verzeichnisstruktur, die sowohl die ausführbaren Dateien als auch alle benötigen Ressourcen enthält, die von einer Applikation benötigt werden. Diese Struktur ist von Apple genau definiert.
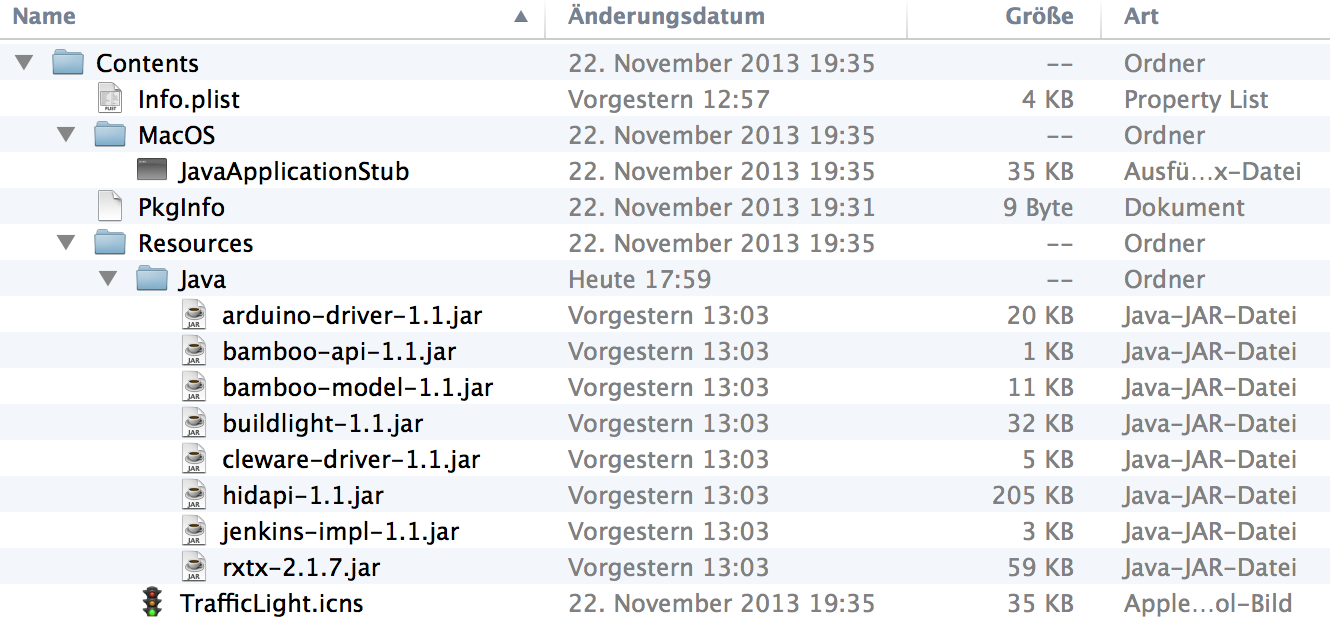
Ein Application Bundle enthält die folgenden Verzeichnisse und Dateien:
- Eine Info.plist Datei im Contents Verzeichnis, die wichtige Meta-Informationen enthält, die von Mac OS X benutzt werden, um die Anwendung zu starten. (“Java Dictionary Info.plist Keys”)
- Außerdem sollte eine Datei mit dem Namen PkgInfo in dem Contents Verzeichnis enthalten sein. (“Data Type Registration”)
- Die Icons, die im Dock und im Finder angezeigt werden, befinden sich im Resources Verzeichnis.
- Im Resources Verzeichnis werden außerdem Dateien abgelegt, die für die Ausführung benötigt werden.
- Im MacOS Verzeichnis befinden sich die ausführbaren Dateien.
Wenn man eine Anwendung im App Store veröffentlichen möchte, müssen alle Ressourcen, die von der Anwendung benötigt werden mit der Anwendung ausgeliefert werden. Ansonsten wird die Anwendung von Apple abgelehnt und kann nicht veröffentlich werden. Dieses Konzept scheint sich wunderbar zu eignen um einen Microservice auszuliefern. Meistens hat man in Produktion aber keine Apple Server. Deshalb wäre es wünschenswert ein alternativ Konzept dafür zu haben. Häufig werden Webanwendungen auf einen Linux-Server ausgeliefert. Daher hat die Anwendung noch eine zusätzliche Abhängigkeit zu Infrastruktur und diese Abhängigkeit kann man benutzen, um die Anwendung auszuliefern.
Linux-Paketverwaltung
Die meisten Linux Distributionen verfügen über eine Software-Paketverwaltung. Eine Software-Paketverwaltung ermöglicht die komfortable Verwaltung von Software, die in Paketform vorliegt. Dazu gehören das Installieren, Aktualisieren und Deinstallieren der Software.
Voraussetzung für Paket-Management ist, dass die zu installierende Software als entsprechendes Paket vorliegt. Ein solches Paket wird meistens von einem Betriebssystemanbieter erstellt, angeboten und gepflegt. Software wird meistens verteilt in unterschiedlichen Verzeichnissen des System installiert. Diese Verzeichnisse sind im Filesystem Hierarchy Standard definiert.
Änderungen, welche die Paketverwaltung zur Installation des Pakets am System vornehmen muss, werden von der Paketverwaltung aus dem Paket ausgelesen und umgesetzt. Erkennt die Paketverwaltung dabei, dass noch weitere Software für das Funktionieren benötigt wird (sogenannte Abhängigkeit, z. B. eine Programmbibliothek), aber noch nicht installiert ist, warnt sie entweder oder versucht, die fehlende Software mit den ihr zur Verfügung stehenden Mitteln, z. B. aus einem Repository, nachzuladen und vorweg zu installieren.
Konkrete Beispiele für Programme um Software-Pakete zu installieren sind:
- Das Programm RPM, dass Pakete vom Typ *.rpm installieren und löschen kann und
- das Programm Dpkg, dass Pakete vom Typ *.deb installieren und löschen kann.
Beide können aber keine Abhängigkeiten auflösen, da sie keine Funktionen haben, um Software nachzuladen. Dies können höhere Schichten der Paketverwaltungen wie YUM, APT, pkg-get und andere. Mit YUM oder APT ist es aber somit möglich auch die Abhängigkeiten zwischen Anwendungsserver und Anwendung aus zu drücken. Da ich häufig Ubuntu verwende und ich deshalb mit Deb-Paketen besser vertraut bin, möchte ich diese im folgenden Besprechen. Die Konzepte für Rpm-Pakete sind allerdings ähnlich.
Aufbau ein Deb-Paket
Jedes Deb-Paket besteht aus drei Dateien, die mittels des UNIX-Kommandos ar oder dem debianspezifischen Kommando dpkg-deb entpackt werden können:
- debian-binary: eine Textdatei mit der Versionsnummer des verwendeten Paketformats.
- control.tar.gz: ein gepacktes Archiv, dass Dateien enthält, die zur Installation dienen oder Abhängigkeiten auflisten. Hier werden nur ein paar Beispiele aufgeführt. Weiterführende Beschreibungen dazu finden sich z. B. in der Offiziellen Debian FAQ zu .deb Paketen.
- control enthält eine Kurzbeschreibung des Paketes sowie weitere Informationen, wie dessen Abhängigkeiten.
- md5sums enthält MD5-Prüfsummen aller im Paket enthaltenen Dateien, um Verfälschungen erkennen zu können.
- conffiles listet die Dateien des Paketes auf, die als Konfigurationsdateien behandelt werden sollen.
- preinst, postinst, prerm, postrm sind optionale Skripte, die vor oder nach dem Installieren, Aktualisieren oder Entfernen des Pakets ausgeführt werden. Sie werden mit den Rechten des Nutzers root ausgeführt.
- data.* Ist ein mit komprimiertes Archiv und enthält die eigentlichen Programmdaten mit relativen, beim Stammverzeichnis beginnenden Pfaden.
Integration in das Buildsystem
Mit jdeb gibt es eine Bibliothek, die einen Ant task und ein Maven Plugin bereitstellt um Debian Pakete zu erstellen. Diese Bibliothek ist Plattform unabhängig und baut Debian Pakete ohne die Installation von irgendwelchen zusätzlichen Tools.
Natürlich gibt es auch ein Gradle-Plugin das Debian Pakete baut. Das Plugin basiert auch auf jdeb und stellt eine Brücke zwischen jdeb und Gradle dar. Das folgende Listing zeigt die Verwendung des Plugins zusammen mit dem Application Plugin:
apply plugin: 'application'
apply plugin: 'pkg-debian'
debian {
packagename = "product"
publications = ['mavenStuff']
controlDirectory = "${projectDir}/debian/control"
changelogFile = "${projectDir}/debian/changelog"
outputFile = "${buildDir}/debian/${packagename}_${version}.deb"
data {
dir {
name = "${projectDir}/debian/data"
exclusions = ["**/.DS_Store", "changelog"]
}
dir {
name = "${buildDir}/debian-data/"
exclusions = ["**/.DS_Store"]
}
file {
name = "${projectDir}/src/main/resources/application.conf"
target = "etc/product/application.conf"
mapper {
fileMode = "755"
}
}
}
}
task prepareDeb {
dependsOn installApp
copy {
from "${buildDir}/install/"
into "${buildDir}/debian-data/usr/share/"
}
}
Zusammenfassung
Die Microservices-Bewegung erscheint auf den ersten Blick, wie das reaktive Manifest der Fachabteilung. Durch das parallele Bearbeiten von Fachlichkeiten kann das vorher monolithische Deployment von Anwendungen parallelisiert werden und die IT Abteilung schneller liefern. Dadurch erzeugt man aber eine Vielzahl an Deployment-Artifakten, die gemanagt werden müssen. Häufig ist ein monolithisches Deployment aber schon schwer genug. Da sehr viele Abhängigkeiten existieren. Sehr oft werden Anwendungen auf Linuxsystemen ausgeliefert. Diese Abhängigkeit zur Infrastruktur kann man aber auch ausnutzen, in dem man die Paketverwaltung der Linuxsysteme nutzt, um die Anwendungen auszuliefern, man baut dann nicht einfach nur ein Web Archive (WAR Dateien), sondern liefert ein Linux-Paket aus, darin ist alles enthalten, was ein Dienst benötigt, um ordnungsgemäß ausgeführt werden zu können. Die Paketverwaltung löst dann alle Abhängigkeiten auf, damit eine Anwendung/Dienst läuft und führt alle nötigen Schritte zur Installation der Software automatisiert aus. Damit erhält man auf den Linuxsystemen ein Apple ähnliches Deployment und kann sich eine Art App Store in Form eines Repository aufbauen, das die Auslieferung von Software stark vereinfach. Theoretisch ist durch dieses Vorgehen möglich seinen kompletten IT-Stack einfach nur mit einen Befehl auszuliefern , führt man z.B. „apt-get upgrade“ aus, werden alle Pakete wenn möglich auf verbesserte Version aktualisiert.

OutOfMemoryError: Java Heapdump Analyse – Was tun? Wenn die Produktion spinnt!
Die Ausnahme java.lang.OutOfMemoryError kann zum Alptraum eines Entwickler werden. Diese Ausnahme tritt oft ohne Vorwarnung, erst unter Volllast in der Produktion auf. OutOfMemoryErrors sind während der Entwicklung nur schwer zu entdecken. Denn häufig wird die Bedeutung von automatisierten Lasttest unterschätzt, die ein solches Szenario simulieren könnten. Kommt es in Produktion zum Super-GAU und die Applikation steigt mit einem OutOfMemoryError aus, dann geht für den Entwickler die forensische Arbeit los. Dabei gilt es herauszufinden, in welchen Situationen die Applikation zu viel Speicher benötigt und wie man vermeiden kann, dass die Applikation abstürzt. In diesem Beitrag geht es darum, wie man bei der Analyse eines solchen Fehlers vorgeht. Um diese Ausnahme besser zu verstehen, wird zuerst die Java Memory Architektur vorgestellt.
Java Memory Architektur
Die Java Plattform verfügt über eine automatische Speicherverwaltung, die in der Java Virtual Machine Specification festgelegt ist. Zur Laufzeit wird zwischen verschiedenen Speicherbereichen unterschieden. Es gibt einen Speicherbereich, der für alle Threads sichtbar. Dieser Speicherbereich enthält unter anderen das sogenannte Method Area (PermGen) und den Heap. Ein anderer Speicherbereich ist exklusiv nur für den ausgeführten Thread sichtbar.
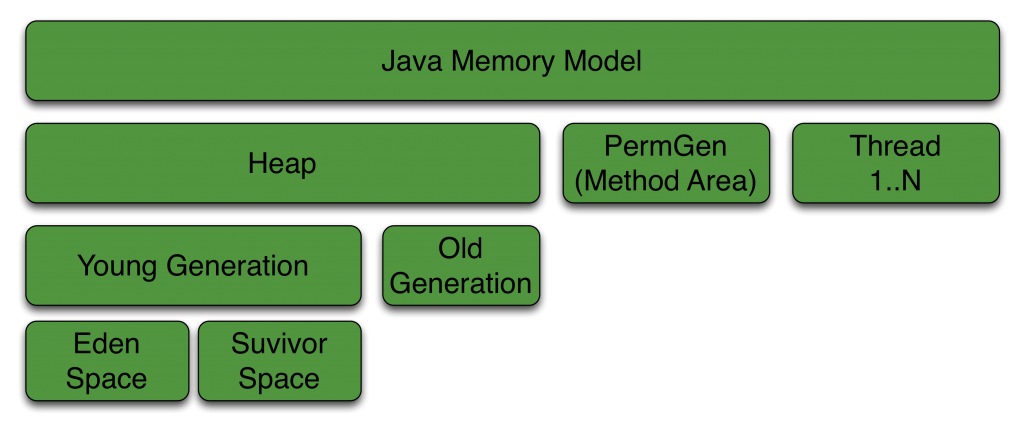
Das Method Area wird beim Start der JVM initialisiert und darin befinden sich die geladenen Klassen. Der Heap verwaltet hingegen alle Objekte und Arrays, die zur Laufzeit erzeugt werden. Der Heap ist für alle Threads sichtbar.
Die JVM Spezifikation sieht weiterhin eine automatische Speicherverwaltung des Heaps in Form einer sogenannten Garbage Collection vor, die vom Garbage Collector durchgeführt wird. Bei der Garbage Collection handelt es sich, um eine explizite Deallokation von Objekten auf dem Heap, die automatisch abläuft. Eine Garbage Collection sollte normalerweise ohne das Zutun eines Entwicklers ablaufen.
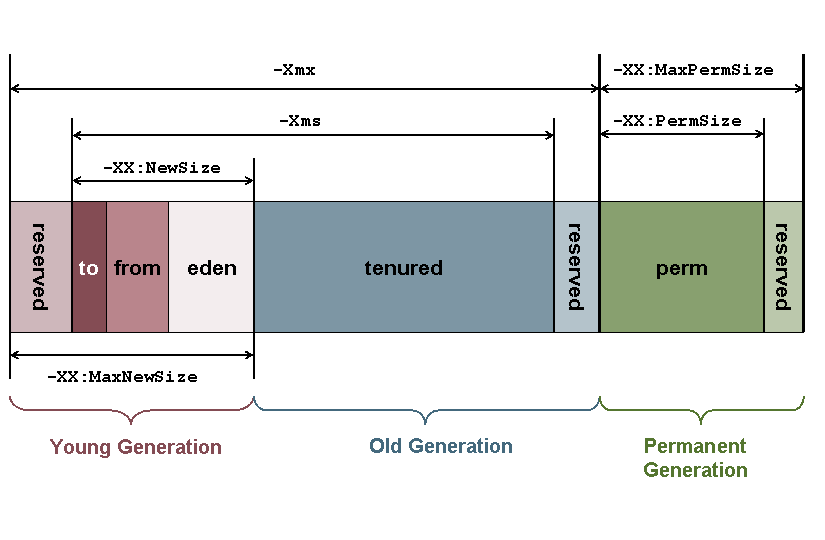
Abbildung 2 zeigt den Aufbau der Oracle HotSpot Implementierung des Heaps und die JVM-Parameter, die man benutzen kann, um den Speicher an entsprechenden Stellen zu vergrößern. Der Heap ist in mehreren Generationen unterteilt: Der Young Generation und der Old Generation. Die Young Generation sorgt für eine Optimierung der Garbage Collection. Außerdem soll die Young Generation die Allokation neuer Objekte, sowie die Deallokation nicht mehr benötigter Objekte vereinfachen. Wenn Objekte ein gewisses Lebensalter überschritten, werden sie in die langsamere Old Generation kopiert. Neben diesen beiden Generationen gab es bis Java 8 noch die Permanent Generation. Im Zuge der Vereinigung der Codebasis der HotSpot und JRockit JVM wurde die Permanent Generation allerdings entfernt (Quelle).
Nachdem nun der Aufbau der Java Memory Architektur geklärt ist, betrachten wir im Folgenden , wie man Java Memory Architektur überwachen kann.
Überwachung der Java Memory Architektur
Die Java Plattform bringt eine Reihe von Werkzeugen mit, um die Java Memory Architektur zu überwachen. Das einfachste Werkzeug ist das Konsolen-Programm jmap. jmap gibt dem Benutzer textuelle Informationen über die verfügbaren JVM Speicherbereiche auf der Konsole aus, wie Young Generation und Old Generation. Das folgende Listing zeigt den Aufruf, den man in der Konsole ausführen muss, um sich Information über den Java-Heap mit jmap anzeigen zu lassen. Zunächst muss man mit dem Konsolenprogramm jps die Prozess-ID des Java Prozesses ermitteln, den man überwachen möchte. Dann kann man mit der herausgefundenen Prozess-ID und dem Parameter -heap das Programm jmap aufrufen und erhält Informationen über den verfügbaren Speicher:
bernd@mbp ~ $ jps 7409 Runner 25297 Jps bernd@mbp ~ $ jmap -heap 7409 ... Heap Usage: PS Young Generation Eden Space: capacity = 60817408 (58.0MB) used = 24817576 (23.667884826660156MB) free = 35999832 (34.332115173339844MB) 40.80669797700027% used ... 13008 interned Strings occupying 1759648 bytes.
Natürlich gibt es auch grafische Werzeuge, um die Java Memory Architektur zu überwachen. Im Folgenden werden die beiden Tools JConsole und VisualVM kurz vorgestellt.
JConsole ist eine Swing-Applikation, die seit Java Version 1.5 mit dem JDK mitgeliefert wird und zur Überwachung von Java Prozessen via JMX auf lokalen oder entfernten Systemen dient. JMX steht für Java Management Extension und ist eine Weiterentwicklung eines Java Standards, der auch die Kommunikation zwischen unterschiedlichen Java Prozessen ermöglicht.
Last login: Wed Apr 30 19:51:45 on ttys000 bernd@mbp ~ $ jconsole
Nach dem Start von JConsole auf der Kommandozeile erscheinen im einem Startscreen alle lokalen Java-Prozesse, diese können mit einem Doppelklick überwacht werden. Für das Monitoring entfernter JVM’s muss auf dem Zielsystem der entsprechende RMI-Zugriff aktiviert sein.

Last login: Thu May 1 10:08:40 on ttys003 bernd@mbp ~ $ jvisualvm
VisualVM ist ein weiteres grafisches Werkzeug mit einfachen Profiling-Möglichkeiten, dass auch über eine grafischen Oberfläche für das JDK-Tool jstack verfügt, mit dem Threaddumps erstellen werden können. VisualVM ist Bestandteil des JDK 6. Innerhalb der JDK heißt VisualVM allerdings Java VisualVM und kann mit dem Befehl jvisualvm in der Kommandozeile aufgerufen werden. Die aktuelle Version von VisualVM findet sich auf der Webseite und kann getrennt von der JVM installiert werden.
Da wir nun wissen, wie wir die JVM überwachen können, sollten wir als Nächstes betrachten, welche Arten der Ausnahme java.lang.OutOfMemoryError auftreten können.
Arten von OutOfMemoryError
Ein Speicherüberlauf tritt immer dann auf, wenn der Garbage Collector keinen Speicher mehr deallokieren kann, um eine Speicheranfrage für das Instanzieren eines neuen Objekts zu erfüllen. Ein solcher Fehler führt zu einem java.lang.OutMemoryError, der sich in einer der folgenden textuelle Beschreibung äußert:
| OutOfMemoryError | Bedeutung |
|---|---|
| Java heap space | Der Garbage Collector kann keinen Speicher mehr freimachen, um eine Speicheranfrage für ein neues Objekt zu erfüllen. |
| Requested array size exceeds | Es wird versucht ein Array auf dem Heap anzulegen, das größer ist als der Heap selber. |
| PermGen space | Es steht nicht genug Speicher zur Verfügung, um Klassen Informationen im Method Area abzulegen oder der Code Cache vollläuft. |
| unable to create new native thread | Es existieren zu viele Threads innerhalb der JVM. Es steht nicht mehr genug Speicher zur Verfügung , um einen neuen nativen Thread anzulegen. |
| request | Der Heap muss erweitert werden, aber auf Betriebssystem Seite steht nicht mehr genügend Speicher zur Verfügung. |
| GC overhead limit exceeded | Der Garbage-Collector ist überdimensional oft und zu lange aktiv, so dass das eigentliche Programm nicht mehr vorankommt. |
Nachdem nun die unterschiedlichen OutMemoryErrors kurz vorgestellt worden, wird im Folgenden genauer betrachtet, wie ein solcher Fehler entsteht und wie man ihn aufspüren kann.
Java Memory Leaks
Alle Objekte werden auf dem Heap erzeugt. Die Lebensdauer eines Objekts auf dem Heap ist abhängig davon, ob das Objekt von einem anderen Objekt referenziert wird. Der Garbage Collector prüft, wenn bestimmte Schwellwerte überschritten werden, ob ein Objekt noch referenziert ist. Sollte ein Objekt nicht mehr referenziert sein, wird das Objekt vom Garbage Collector als „Müll“ markiert und in einem späteren Schritt aufgeräumt und dessen Speicher freigegeben.
Sogenannte Garbage Collector Root (GC Root) Referenzen sind für das Überleben eines Objekts entscheidend. Ein GC Root ist ein Objekt, auf das es keine eingehenden Referenzen gibt. GC Roots sind verantwortlich dafür, dass referenzierte Objekte im Speicher gehalten werden. Wird weder direkt noch indirekt von einem GC Root referenziert, wird ein Objekt es als “unreachable” gekennzeichnet und zur Garbage Collection freigegeben. Man kann die folgenden Arten von Garbage Collection Roots unterscheiden:
- Temporäre Variablen auf dem Stack eines Threads
- Statische Felder von Klassen
- Spezielle native Referenzen in JNI
GC Root lassen sich am besten anhand eines konkreten Code-Beispiels verdeutlichen:
public class MyPage extends org.apache.wicket.markup.html.WebPage {
//Die Liste ist erreichbar,
//wenn die Klasse geladen ist
public static final List STATIC = new ArrayList();
//Die Liste ist erreichbar,
//solange eine Instanz der Seite existiert
private final List instance = new ArrayList()
//Die Liste ist erreichbar,
//solange die Methode ausgeführt wird
//auch wenn die Liste nicht benutzt wird
private void myMethod(List parameter) {
//solange die Methode ausgeführt wird
//ist die List von Stack erreichbar
List local = new ArrayList();
}
}
GC Root Objekte sind für die folgenden OutOfMemoryError Problemen verantwortlich:
- Objekte, die nie mehr im Anwendungscode genutzt werden, aber noch eine GC Root Referenz haben, verursachen Java Memory Leaks, da diese Objekte nicht vom Carbage Collector aufgeräumt werden können.
- Durch die Verwendung von großen Objektbäume, die im Speicher gehalten werden (z.B. Caches), kann es dazu kommen, dass nicht genug Heap zu Verfügung steht. Dann muss der Speicher für die Applikation erhöht werden.
- Zu viele temporäre Objekte, die dazu führen, dass temporär bei der Verarbeitung im Java-Code zu viel Speicher benötigt wird.
Java Memory Leaks entstehen immer dann, wenn ein Objekt noch eine GC Root Referenz hat, aber nicht mehr in der Anwendung benutzt wird. Solche Objekte werden „Loitering Objects“ genannt. Loitering Objects belegen für die komplette Ausführungsdauer den JVM Speicher. Durch solche „Objekt-Leichen“ wird der Anwendungsspeicher nicht mehr ausreichen und es kommt zu einem OutOfMemoryError. Häufig wird ein OutOfMemoryError von statischen Collections ausgelöst. Dann werden Objekte der Collection hinzugefügt, aber nicht wieder gelöscht. Die hinzugefügten Objekte werden durch die statischen Collection-Einträge referenziert und können aufgrund der GC Root Referenz (statisch) nicht mehr freigegeben werden.

Im Zusammenhang mit Java Memory Leaks wird weiterhin oft von sogenannten Dominatoren und Dominatorbäumen gesprochen. Bei Dominatoren handelt es sich, um ein Konzept aus der Graphentheorie. Ein Dominator ist ein Knoten, durch den ein kompletter Teilgraph erreichbar ist. Auf das Speichermanagement umgesetzt, heißt das, dass ein Objekt A ein Dominator eines anderen Objekts B ist, wenn es kein weiteres Objekt C gibt, das eine Referenz auf B hält. Wird also die Wurzelreferenz freigegeben, wird auch der ganze Dominatorbaum freigeben. Sehr große Dominatorenbäume sind also sehr gute potenzielle Kandidaten bei der Memory Leak Suche.
Die Memory Leak Suche beginnt mit dem Erstellen eines Heapdump. Im Folgenden werden zunächst Möglichkeiten vorgestellt, um einen Heapdump zu erstellen.
Java Heapdump
Ein Heapdump ist eine textuelle oder binäre Abbildung des Java Heaps. Aus den Informationen, die in einem Heapdump enthalten sind, lassen sich mit verschiedenen Werkzeugen die gesamten Objekte, die von einer Applikation erzeugt werden, rekonstruieren. Außerdem sind alle Referenzen zwischen den Objekten in einem Heapdump enthalten. Ein Heapdump kann im Fehlerfall durch die JVM Option -XX:+HeapDumpOnOutOfMemoryError beim Auftreten eines OutOfMemoryErrors automatisch erzeugen werden. Heapdumps enthalten meistens die folgenden Arten von Objekten:
- lebendige Objekte, das sind Objekte, die über eine GC Root Referenz erreichbar sind
- Alle nicht mehr referenzierten Objekte
Alternativ zur JVM Option kann ein Heapdump mit dem Konsolen-Werkzeug jmap erstellt werden, das wir bereits zur Überwachung der JVM kennengelernt haben. Das folgende Listing zeigt, wie man einen Heapdump über die Konsole erstellen kann.
bernd@mbp ~ $ jps 16497 AppMain 16520 Jps bernd@mbp ~ $ jmap -dump:live,format=b,file=dump.hprof 16497 Dumping heap to /Users/berndzuther/dump.hprof ... Heap dump file created
Natürlich gibt es auch ein grafische Werkzeug, wie z.B. VisualVM, mit dem man auch einen Heapdump erstellen kann.
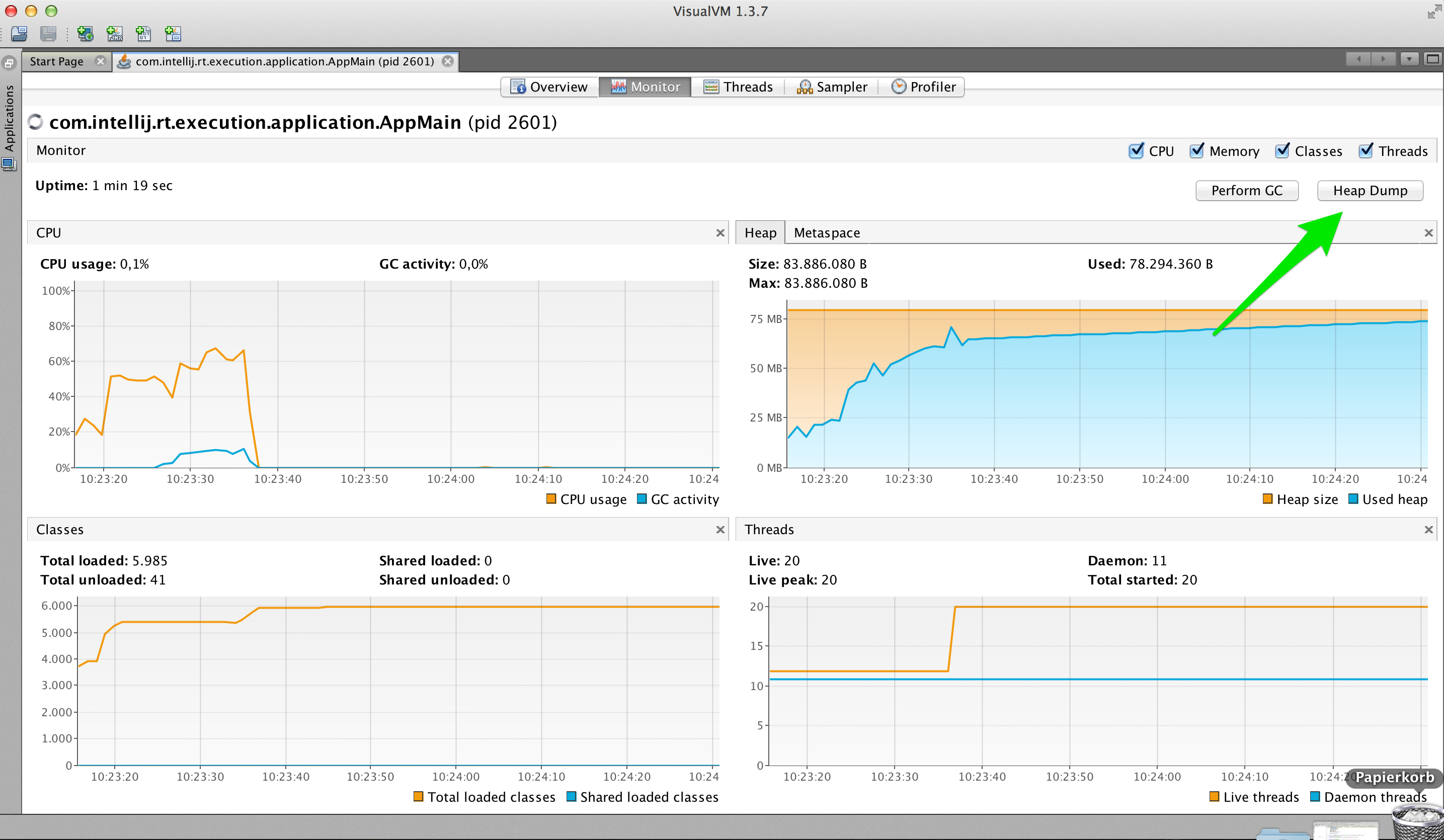
Nachdem wir nun einen Heapdump erzeugen können, können wir beginnen den Heapdump zu analysieren. Dazu stehen uns die folgenden Tools zur Verfügung.
Heapdump Analyse
Das JDK 1.6 bringt ein kleines Tool mit Namen jhat (Java Heap Analysis Tool) zur Analyse von Heapdumps mit. jhat startet einen lokalen Webserver. Der Heapdump kann unter Verwendung der Defaulteinstellungen über die Adresse http://localhost:7000 analysiert werden. Das Tool stellt aber leider nur sehr rudimentäre Funktionen zur Auswertung des Heapdumps zur Verfügung und ist es nicht sehr gut zu bedienen.
bernd@mbp ~ $ jhat -J-mx2000m dump.hprof Reading from dump.hprof... Dump file created Fri May 02 18:37:18 CEST 2014 Snapshot read, resolving... Resolving 2013119 objects...
Ein schönes Werkzeug für die Analyse von Heapdumps ist der Memory Analyzer (MAT), der in der Lage ist sehr große Heapdumps zu verarbeiten. Ältere Tools haben oft das Problem, dass der Heapdump zur Analyse komplett in den Arbeitsspeicher geladen werden muss und man i.d.R. das 1,5-fache des Heaps zur Analyse benötigt. D.h. ein Heap von 2GB Größe benötigte 3 GB Heap zur Analyse. Der Memory Analyzer indiziert zunächst einen Heapdump, um hinterher in vertretbarer Zeit und mit verkraftbarem Speicherverbrauch eine Analyse auf dem Dump ermöglichen zu können.
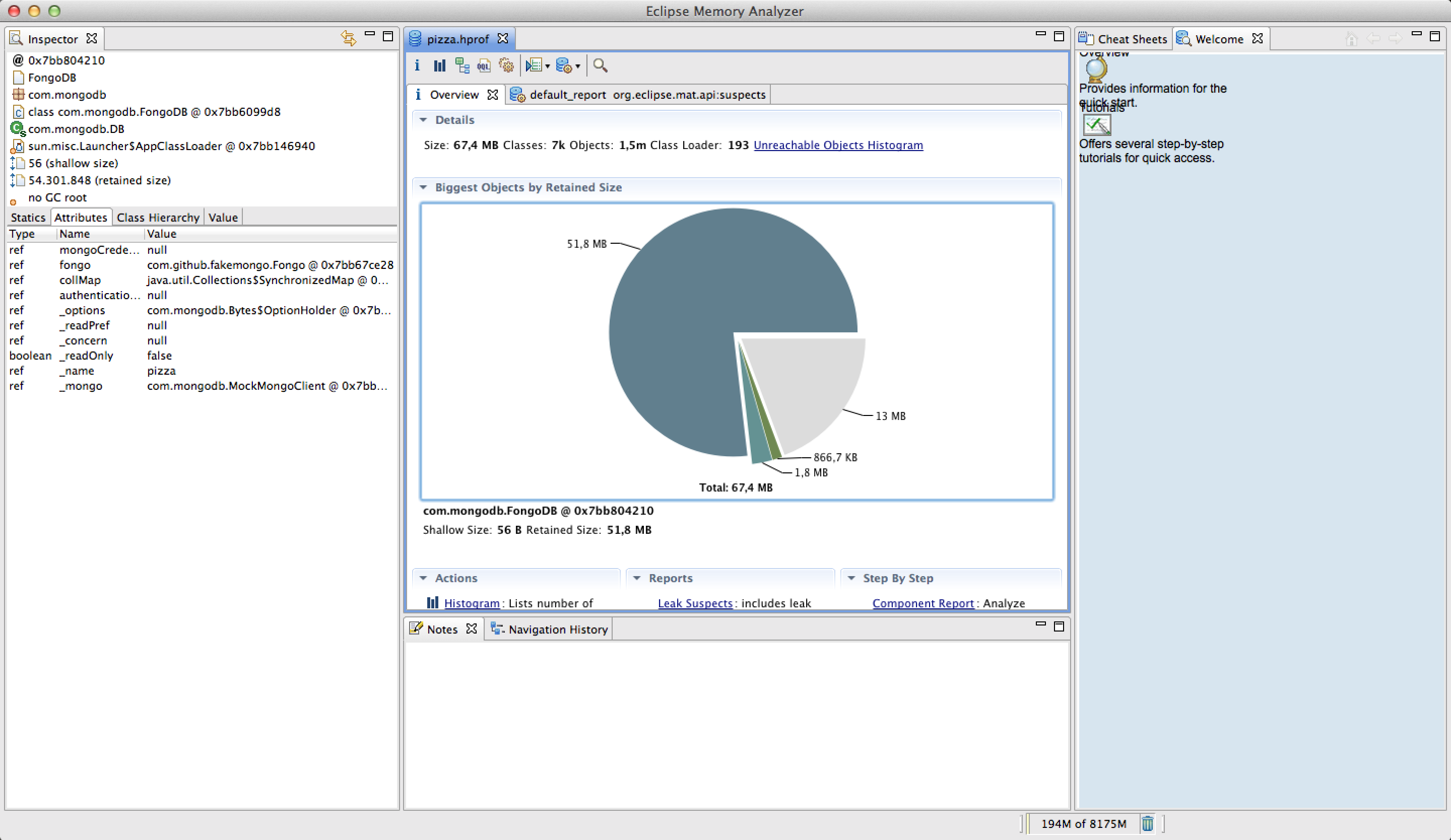
Der Memory Analyzer analysiert die Referenzbeziehungen zwischen Objekten auf dem Heap und erzeugt daraus Dominatorbäume. Außerdem sucht der Memory Analyzer die Dominatoren im Heap (diese werden im MAT Akkumulierungspunkte genannt) heraus. Die Dominatoren erhalten große Mengen Speicher am Leben und werden als „Suspect Report“ dargestellt, wie es in Abbildung 9 zu sehen ist.

Um Objekte in einem Heapdump abzufragen, gibt es die sogenannte Object Query Language (OQL). OQL führt bei Abfragen zu mehr Flexibilität und ermöglicht es Objekte nach bestimmten Kriterien zu filtern. Dazu benutzt OQL die JavaScript Expression Language.
Eine OQL Anfrage hat die folgende Struktur:
select
[ from [instanceof]
[ where ] ]
--selektiert alle Strings, die mehr als 100 Zeichen haben
select s from java.lang.String s where s.count >= 100
--selektiert alle int arrays mit mehr als 256 Elementen
select a from int[] a where a.length >= 256
Im nächten Schritt führen wir eine Java Heap Analyse mit dem Memory Analyzer an einem konkreten Beispiel aus.
Online Shop – Beispiel Heapdump-Analyse
Die Firma comSysto hat im Rahmen des Meetup „Boost your Java Enterprise Stack with MongoDB„ einen Onlineshop in seinen Github Repository veröffentlicht. Das folgende Youtube-Video zeigt, über welche Funktionalität dieser Onlineshop verfügt und gibt eine kleine Einführung in den Onlineshop.
[youtube http://www.youtube.com/watch?v=uJpFp9qR4Z4&rel=0&hd=1]
Im Folgenden verwenden wir einen Fork dieses Onlineshop, um eine Memory Leak Analyse durchzuführen. Diesen Fork kann man in meinem Github Repository auschecken. Das folgende Listing zeigt, was dazu zu tun ist:
bernd@mbp ~ $ git clone https://github.com/zutherb/memory-leak-detection.git Cloning into 'memory-leak-detection'... remote: Counting objects: 1231, done. remote: Compressing objects: 100% (632/632), done. remote: Total 1231 (delta 211), reused 1231 (delta 211) Receiving objects: 100% (1231/1231), 5.72 MiB | 1.56 MiB/s, done. Resolving deltas: 100% (211/211), done. Checking connectivity... done. bernd@mbp ~ $ cd memory-leak-detection bernd@mbp ~/memory-leak-detection (master)$ git branch -r origin/HEAD -> origin/master origin/master origin/memory-leak-fix
Manchen wir uns im nächsten Schritt mit dem Repository vertraut. Das Repository verfügt über zwei Branches. Der master-Branch ist mit einem Memory Leak präpariert und im memory-leak-fix-Branch befindet sich der Onlineshop in einer Memory Leak freien Version.
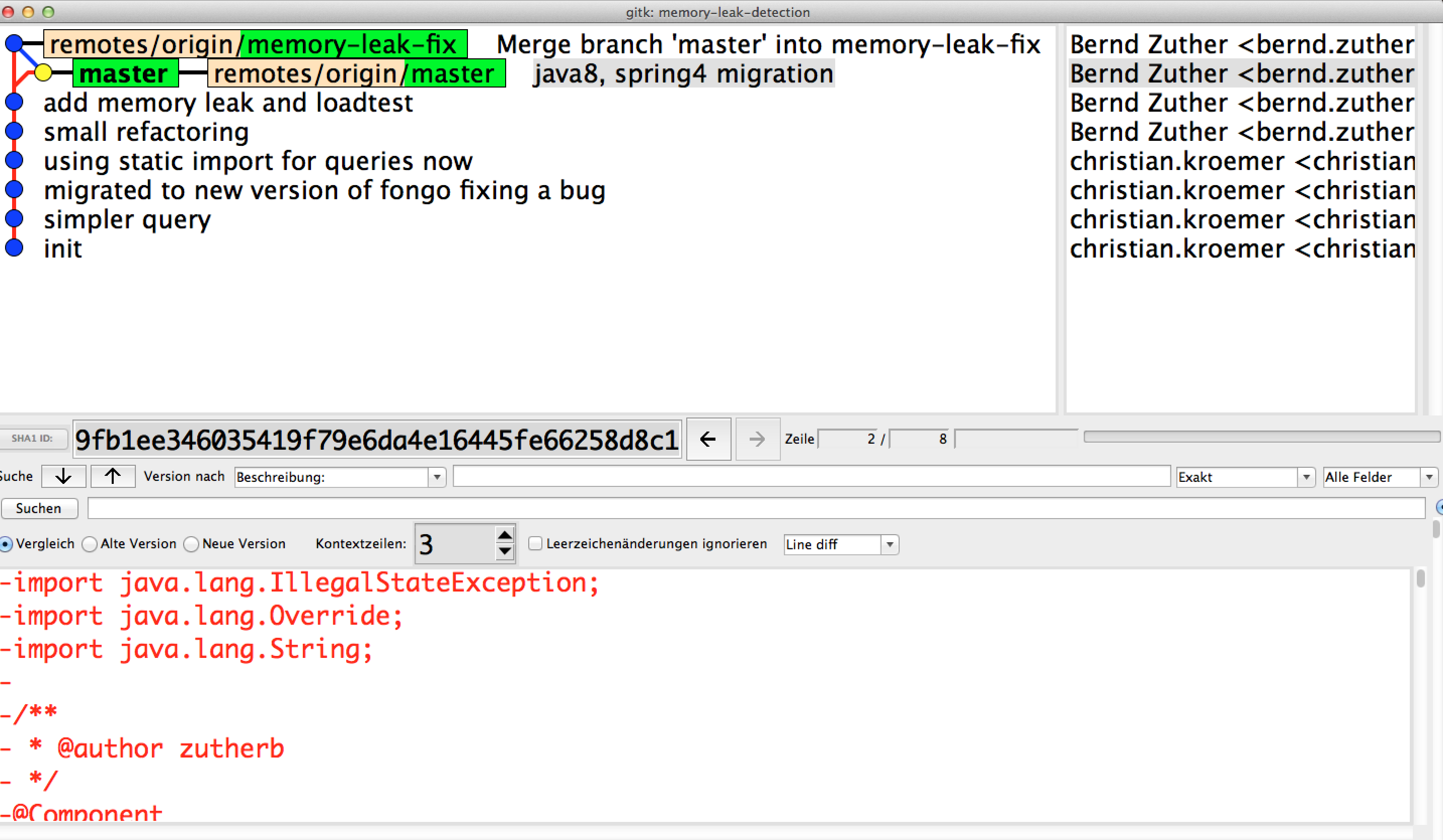
Nachdem wir nun den Aufbau des Repository kennen, können wir uns mit dem Onlineshop selbst vertraut machen. Der Onlineshop basiert auf Java 8. Um den Onlineshop bauen und starten zu können, muss also auch Java 8 auf dem Rechner installiert sein und das entsprechende Java_Home als Umgebungsvariable eingestellt sein. Als Buildtool wird Gradle verwendet, das schon aus dem Artikel „Gradle: Erstellen von einem Java Application Bundle unter Mac OS X“ bekannt ist. Gradle ist ein auf Groovy und Java basierendes Build-Management-Automatisierungs-Tool, dass vergleichbar mit Apache Ant und Apache Maven ist. Gradle nutzt jedoch im Gegensatz zu Maven und Ant eine auf Groovy basierende domänenspezifische Sprache (DSL) zur Beschreibung der zu bauenden Projekte. Gradle muss nicht auf dem Rechner installiert sein, man kann den sogenannten Gradle-Wrapper benutzen, der sich im Wurzel-Verzeichnis des Projektes befindet. Um das Projekt zu bauen und die Anwendung zu starten. Hierzu nutzen wir den Task jettyRun im Projekt shop/ui. Nach einer Weile startet der Onlineshop auf der Url http://localhost:8080/pizza. Das folgende Listing zeigt, wie man unter MacOSX das JAVA_HOME für Java 8 setzen kann (VORRAUSSETZUNG: Java 8 ist installiert) und den Onlineshop startet:
bernd@mbp ~/mld $ export JAVA_HOME="${/usr/libexec/java_home -v 1.8}"
bernd@mbp ~/mld (master)$ ./gradlew -p shop/ui/ jettyRun
Die Katalog-Seite des Onlineshop ist mit einem Memory Leak präpariert. Dieser äußert sind in einem OutOfMemoryError: Java Heap Space, wenn man die Katalog-Seite oft genug aufruft. Um nicht ständig die Katalog-Seite http://localhost:8080/pizza/productcatalog/pizza per Hand aufrufen zu müssen, befindet sich im Verzeichnis external die Datei loadtest.jmx. Diese Datei kann man mit dem Programm Apache JMeter ausführen. JMeter ist ein freies, in Java geschriebenes Werkzeug zum Ausführen von Lasttests in Client/Server-Anwendungen. JMeter ermöglicht es durch das Zusammenstellen eines Testplanes zu spezifizieren, welche Teile der Anwendung durchlaufen werden sollen, um konkrete Ergebnisse über das Antwortzeitverhalten zu bekommen.
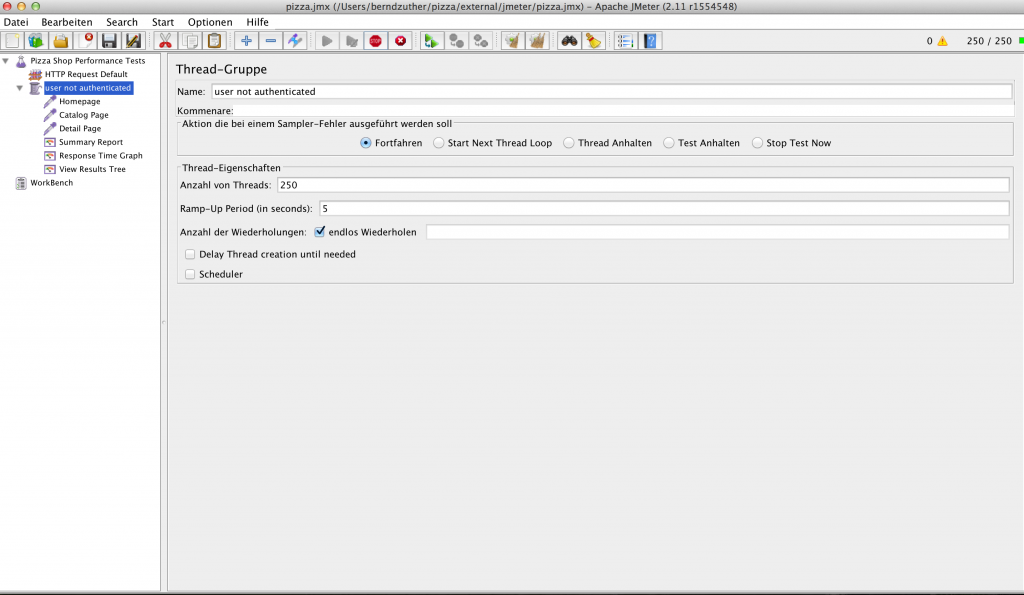
Öffnen wir JMeter und führen die Datei loadtest.jmx gegen den laufenden Shop aus, in dem wir auf den grünen Play-Button unterhalb der Menü-Liste in JMeter klicken. Nach einiger Zeit kommt es zu einem OutOfMemoryError: Java heap space.
Error for /pizza/productcatalog/pizza java.lang.OutOfMemoryError: Java heap space
Jetzt ist der Moment erreicht, in dem wir einen Heapdump erstellen sollen. Das folgende Listing zeigt, wie wir mittels jps die Prozess-ID des laufenden Onlineshops herausfinden können, um einen Heapdump erstellen zu können. Denn ersten jps Aufruf sollte man machen bevor, man mit Gradle den Onlineshop startet. In der Regel ist aber die höchste Prozess-ID des GradleDaemon auch die Prozess-ID des laufenden Onlineshops.
bernd@mbp ~/memory-leak-detection (master)$ jps 6097 535 WrapperSimpleApp 4509 GradleDaemon 6404 Jps bernd@mbp ~/memory-leak-detection (master)$ jps 6097 535 WrapperSimpleApp 6451 GradleDaemon 4509 GradleDaemon 6481 Jps 6441 GradleWrapperMain bernd@mbp ~/memory-leak-detection (master)$ jmap -dump:live,format=b,file=dump.hprof 6451 Dumping heap to /Users/berndzuther/memory-leak-detection/dump.hprof ... Heap dump file created
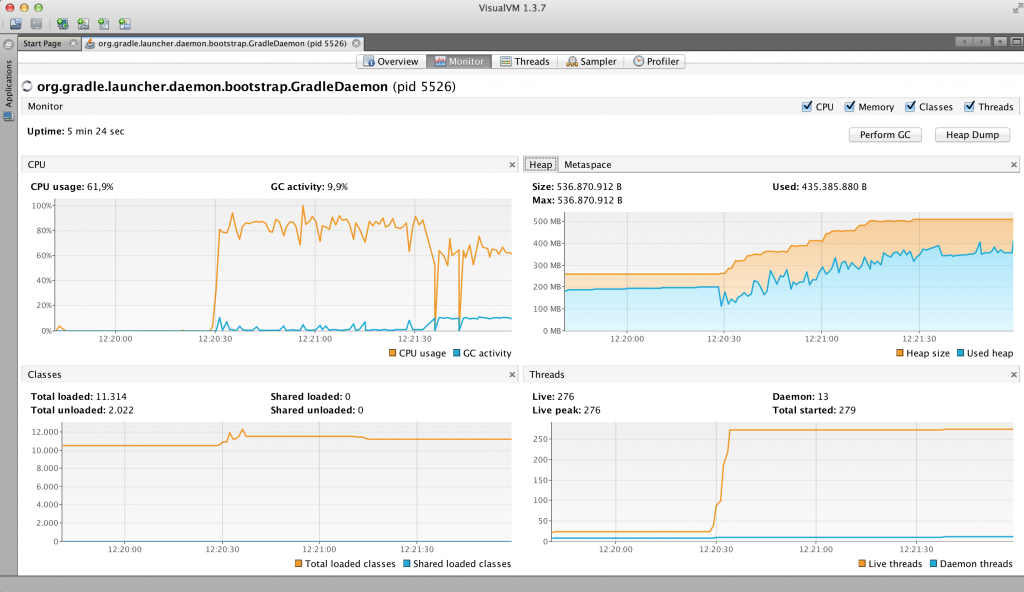
Natürlich kann man den Onlineshop auf während des Lasttests mit VisualVM überwachen. Dann kann man dabei zu gucken, wie der Heap Speicher vollläuft, wie es in Abbildung 13 zusehen ist.
Wenn wir den Dump nun in den Memory Analyzer laden und einen Suspect Report erstellen, warnt uns der Memory Analyzer vor einem potentiellen Memory Leak in der Klasse ProductCatalogPage.
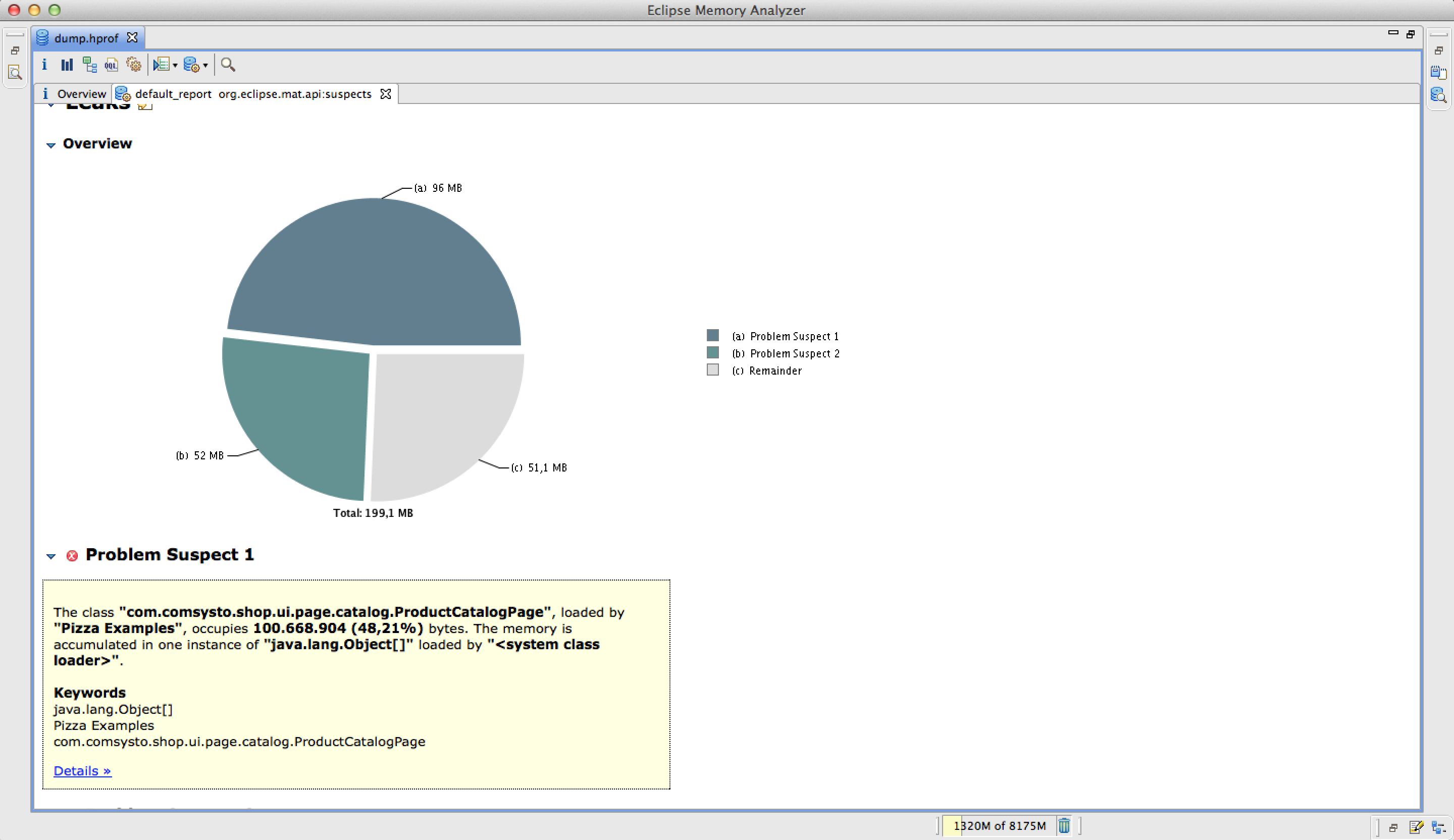
In unserem Beispiel wird eine ArrayList als Hauptverdächtiger präsentiert. Durch das verdächtige Objekt wird circa die Hälfte, des Speichers verbraucht, der der Anwendung zur Verfügung steht. Als nächstes kann man sich eine detailliere Beschreibung ausgeben lassen, in dem man auf Details klickt. In dieser Ansicht sieht man, was die verdächtige ArrayList enthält und wer die ArrayList referenziert. Auch diese Information ist im Memory Analyzer gut aufbereitet:
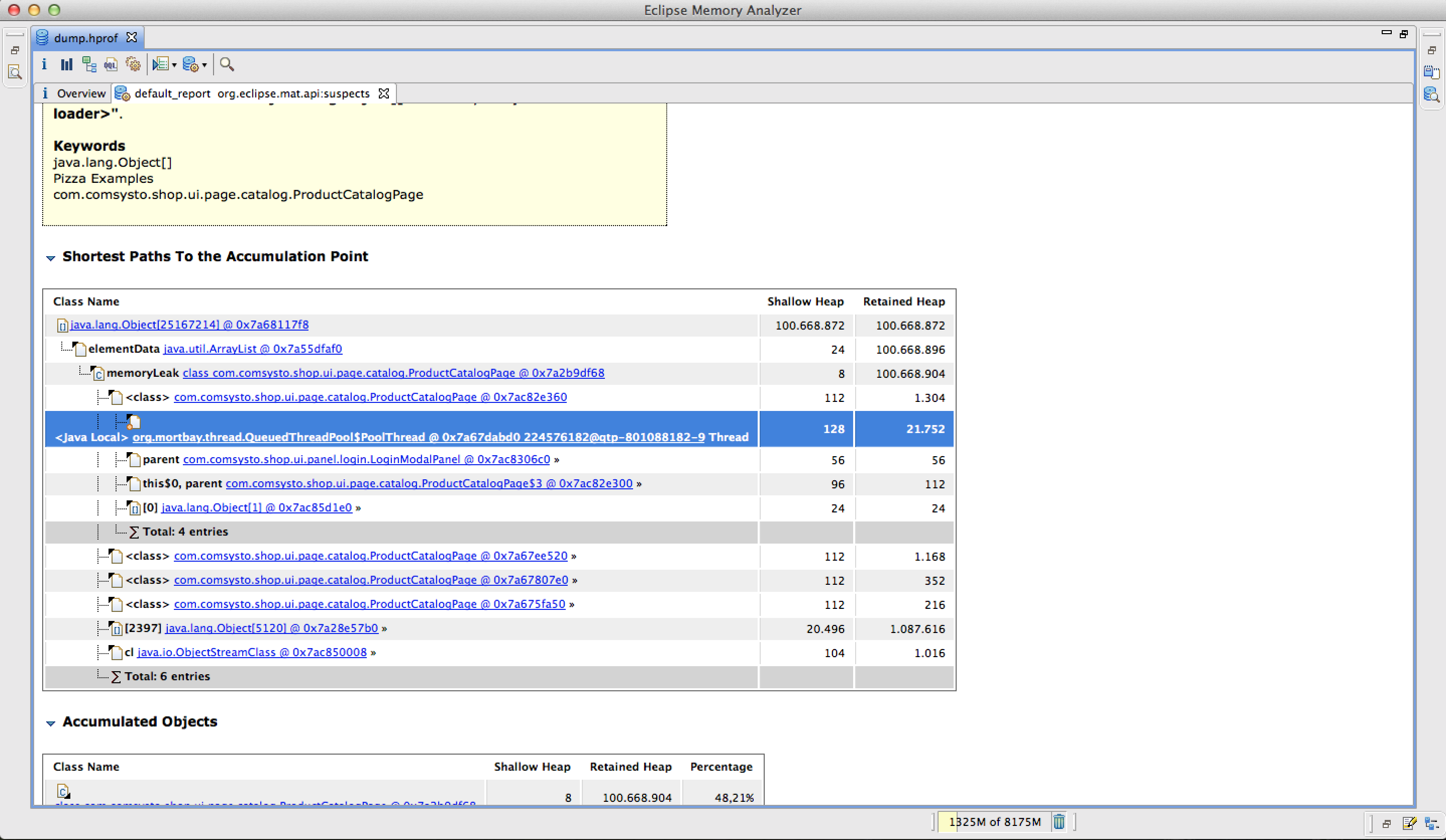
In der Accumulation Point Ansicht des Suspect Report sieht man, das die Klasse ProductCatalogPage eine Variable memoryLeak enthält, die die verdächtige ArrayList referenziert. Ein Blick in den Quellcode verrät uns, dass es sich dabei um eine statische Variable handelt, die bei jeden rendern des Produkt-Katalogs immer wieder alle Elemente im Katalog in sich und sich danach selbst kopiert. Wenn man die Liste entfernt, kann man den Lasttest ausführen, ohne das es zu einem OutOfMemoryError kommt. Damit haben wir das Memory Leak in der Applikation gefunden und beseitigt.
@MountPath("productcatalog/${type}")
@EnumProductTypeNavigationItem(enumClazz = ProductType.class, defaultEnum = "PIZZA", sortOrder = 2)
public class ProductCatalogPage extends AbstractBasePage {
@SpringBean(name = "productService")
private ProductService productService;
private IModel productTypeModel;
private IModel productListModel;
private Component basketPanel;
private static List memoryLeak = new ArrayList();
...
private Component productView() {
return new DataView("products", productDataProvider()) {
@Override
protected void populateItem(final Item item) {
memoryLeak.add(item.getModelObject());
memoryLeak.addAll(new ArrayList<>(memoryLeak));
...
}
};
}
...
}
Auch in Dominatorbaum Ansicht, die in Abbildung 15 dargestellt wird, sieht man, dass es sich bei der ArrayList, um einen potenziellen Kandidaten für einen Memory-Leak handelt.

Zusammenfassung
In diesem Artikel haben wir die Suche nach Memory Leaks mit Hilfe eines Heapdumps betrachtet. Ein Heapdump kann z.B. mit dem Konsolen-Programm jmap oder über eine JVM Option im Fehlerfall erstellt werden.
Eine Heapdumps Analyse wird oft post mortem durchgeführt, nachdem die Anwendung bereits wegen einem OutOfMemoryError abgebrochen wurde. Für eine Heapdump-Analyse, kann das frei verfügbare Werkzeug Memory Analyzer MAT verwendet werden, das einen potentielle Kandidaten für einen Memory Leak vorschlägt. Sehr große Dominatorenbäume sind auch sehr gute potenzielle Kandidaten bei der Memory-Leak-Suche.
—————————————————-
Ich danke Daniel Mitterdorfer für die vielen Anregungen und Ideen zu diesem Artikel. Daniel Mitterdorfer ist ein Software Engineer und Mitglied der Application Performance guild bei der comSysto GmbH.
JUGM Talk: Grünes Licht für Continuous Delivery – Bau dein eigenes Extreme Feedback Device
Was musst man tun um „gehighlighten“ Quellcode in Keynote einfügen
Jeder It-ler kennt wahrscheinlich das Problem. Morgen musst er eine Präsentation halten und es gelingt einfach nicht den Quellcode formatiert und eingefärbt in seine Präsentation zu übernehmen. Deshalb hier eine kurze Anleitung, was in dieser Situation zu tun ist:
- Homebrew auf dem Mac installieren, wenn es nicht schon installiert ist
- Highlight Kommandozeilen Tool installieren:
brew install highlight
- Quellcode „hightlighten“ und in die Mac Zwischenablage kopieren:
highlight -O rtf Code.java | pbcopy
- Quellcode in die Keynote Präsentation mit CMD + v einfügen. Fertig.