
Die Software-Entwicklung begibt sich derzeit auf eine neue Evolutionsstufe: Fachabteilungen haben gelernt, mithilfe agiler Methoden Änderungen in kurzen Zyklen produktiv umzusetzen. Damit haben sie die Möglichkeit, Änderungen an einem Produkt mit echtem Benutzer-Feedback vermessen zu können und durch empirische Untersuchungen des Benutzerverhaltens fundierte Entscheidungen über neue Software-Funktionalitäten zu treffen. Dazu müssen aber die meisten IT-Architekturen erst einmal so auf Vordermann gebracht werden, dass einzelne Teile einer Software flexibel ausgetauscht und unabhängig voneinander ausgeliefert werden können.
Microservices und die Jagd nach mehr Konversion – Fluch oder Segen für den Entwickler
Softwareentwicklung wandelt sich derzeit: Es reicht nicht mehr Produktinkremente potenziell produktiv zu setzen, sondern Änderungen müssen produktiv gehen. Um in gesättigten Märkten noch Innovationen hervorzubringen und neues Wachstum zu generieren, arbeiten Fachabteilungen immer öfter mit Lean-Startup-Methoden. Eine Methode im Lean-Startup ist die Bildung von Hypothesen, die durch Tests validiert werden. Dazu wird Software in unterschiedlichen Varianten ausgespielt und dann beobachtet, wie Kunden auf eine Änderungen reagieren. Je nach Test-Ergebnis werden Teile der Software dann wieder entfernt oder angepasst. Somit ist es wichtig Software schnell an den an den Anwender zu bringen.
Software schneller in Produktion zu bringen, ist mit den meisten Softwarearchitekturen nicht so einfach. Häufig existieren monolithische Anwendungen, die kompliziert zu installieren sind und bei denen für kleine Änderungen die Koordination von vielen Teams nötig ist. Um Teile der Software zu entkoppeln und Koordinationsaufwand zwischen den Teams zu verringern, wird häufig vorgeschlagen eine Applikation in kleine Dienste zu zerlegen, oft kurz Microservice-Architektur genannt.
Wir sehen uns an Hand eines konkreten Beispiels an, wie man eine bestehende Architektur in eine Mircroservice-Architektur überführen kann und welche Konsequenzen dies auf technischer Ebene hat. Zum Beispiel führen Microservices zu mehreren Deployment Pipelines und man braucht Konzepte die unterschiedlichen Teile der Software auch schnell auf unterschiedlichen Rechner provisionieren zu können. Außerdem sollte man sich Gedanken zum Thema Logging und dem Monitoring im Betrieb machen, denn sonst kann der Betrieb eines solchen hochverteilten Systems schnell zur Qual werden.
Folien
- slides/zuther/slides/02_bobkonf/index.html
- Quellcode
- https://github.com/zutherb/AppStash/
- Artikel in der Java-Aktuell 02/2015
Deployment ganz einfach – Microservice Deployment mit Hilfe der Linux Paketverwaltung
Softwareentwicklung wandelt sich, anstatt Software für die nächsten Jahre zu planen, zu entwickeln und dann erst dem Kunden zu präsentieren, arbeiten Fachabteilungen oft mit kleinen Hypothesen. Diese Hypothesen werden mithilfe von A/B Tests direkt am Kunden validiert und kommen dann als neue Userstories in den Entwicklungsprozess. Damit werden schrittweise Unternehmensprozesse und bestehende Software optimiert. Durch dieses Vorgehen bauen Fachabteilung Software, die ihre Kunden wirklich wollen. Das stellt die IT-Abteilungen natürlich vor die Herausforderung öfter und schneller ausliefern zu müssen, um schneller von den Testergebnissen profitieren zu können und letztlich mehr Umsatz zu generieren.
Beispielsweise kann eine simple Änderung der Farbe eines Links in einem Online-Shop eine Konvertierungssteigerung von 20% auslösen. Ein solche Änderung ist relativ schnell umgesetzt, doch selbst mit Continuous Delivery und einer Deployment Pipeline kann, der Durchlauf bis in Produktion mehrere Stunden in Anspruch nehmen, was ziemlich viel Geld kosten kann. Es gibt deshalb Stimmen, die meinen, dass solche langen Durchlaufzeiten am architektonischen Aufbau der Anwendungen liegt.
Aufbau von Web-Anwendungen
Web-Anwendungen sind häufig aus den folgenden drei Teilen aufgebaut:
- Einer Benutzerschnittstelle (z.B. HTML),
- einer Datenbank und
- einer Server-Komponente.
Die Server-Komponente kümmert sich um die Abarbeitung der HTTP Requests, führt die Domänenlogik aus, ließt und schreibt Daten aus/in die Datenbank, bestimmt welche Teile der Benutzerschnittstelle ausgeliefert werden müssen. Jede Änderung in diesem System erfordert einen Build und ein Deployment einer neuen Version der kompletten Software. Solche Anwendungen werden auch Monolithen genannt.
Auch wenn Monolithen sehr erfolgreich sein können, gibt es eine steigende Anzahl von Leuten, die mit diesen Ansatz nicht zufrieden sind, weil man auch für kleine Änderungen sehr hohe Durchlaufzeiten bis in Produktion hat und die Entwicklungsteams nicht mehr richtig skalieren, da man immer wieder die komplexen und zeitaufwendigen Buildprozesse der Monolithen durchlaufen muss und Änderungen an der Software immer schwieriger werden. Außerdem skalieren Monolithen schlecht. Wenn man einen solchen Monolithen skalieren möchte, muss man immer die komplette Anwendung verteilen, auch wenn nur bestimmte Teile der Anwendung Performance-Probleme hervorrufen.
Es gibt Stimmen, die meinen, dass die klassische Drei-Schichten nicht mehr gut genug skaliert, um kleine gewinnbringende Features schnell genug ausliefern zu können. Deshalb erfreut sich das Konzept der Microservice-Architektur immer größer Beliebtheit. Ziel ist es die Anwendung entsprechend ihrer Fachlichkeit zuzuschneiden und in kleine Services zu unterteilen, die getrennt von einander ausgeliefert werden können. Damit soll die Durchlauf eines Features bis in Produktion verringert werden.
Die Microservice-Architektur zerschneidet Anwendungen in eine Anzahl an Diensten. Diese Dienste sind eigenständig deploy- und skalierbar. Jeder Dienst stell eine abgrenzte Fachlichkeit bereit, kann in einer beliebigen Programmiersprache implementiert sein und von unterschiedlichen Teams bereitgestellt werden. Zerschneidet man eine Software in eigenständige Dienste erzeugt man natürlich eine Vielzahl an Deployment-Artifakten. Häufig hat der Betrieb aber schon Probleme mit dem Deployment einer einzelnen monolithischen Anwendung. Deshalb muss man einen Weg finden Abhängigkeiten besser aufzulösen, die für eine erfolgreiche Auslieferung benötigt werden.
Deployment von Web-Anwendungen
In der Regel werden Web-Anwendungen in einen Anwendungsserver aufgeliefert. Ein Anwendungsserver stellt einen Container dar, der spezielle Dienste zur Verfügung stellt, wie beispielsweise Transaktionen, Authentifizierung oder den Zugriff auf Verzeichnisdienste, Webservices und Datenbanken über definierte Schnittstellen.
Um das Deployment in einem Anwendungsserver zu standardisieren gibt es das Web Archive oder das Enterprise Archive. Ein Web Archive ist ein Dateiformat, das beschreibt, wie eine vollständige Webanwendung nach der Java-Servlet-Spezifikation in eine Datei im JAR- bzw. ZIP-Format verpackt wird. Bei einem Enterprise Archive handelt es sich ebenfalls um eine Datei im JAR- bzw. ZIP-Format, die ein vollständiges Anwendungsprogramm – meist eine Webanwendung – gemäß dem Standard Java Platform, Enterprise Edition (Java EE) enthält. Leider reichen diese beiden Standards nicht aus, um alle Abhängigkeiten aufzulösen, die eine Anwendung für den fehlerfreien Betrieb benötigen.
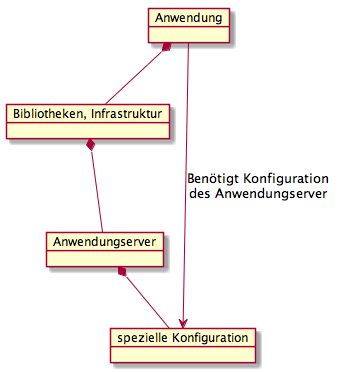
Die Abbildung zeigt die Abhängigkeiten zwischen Anwendung und Anwendungsserver. Eine Anwendung hängt vom Anwendungsserver ab, da die Anwendung Bibliotheken und Infrastruktur des Anwendungsserver nutzt. Umgekehrt ist der Anwendungsserver aber auch von der Anwendung abhängig, da der Anwendungsserver für eine Anwendung speziell konfiguriert werden muss. Damit ist ein Anwendungsserver eigentlich Teil einer Anwendung und man sollte Anwendungsserver und Anwendung als eine Komponente sehen.
Benötigt eine neue Version der Anwendung auch einen neue Version des Anwendungsserver gibt es für den Betrieb häufig viele manuelle Schritte auszuführen, weil diese Abhängigkeiten in eine WAR oder einem EAR nicht ausgedrückt werden können. Diese Abhängigkeiten werden dann oft textuell in Form eines Tickets beschrieben und wenn man Glück hat werden die Instruktionen vom Betrieb richtig ausgeführt. Ähnliches gilt bei Datenbankänderungen. Es wäre deshalb wünschenswert Deployment-Artifakte zu haben, die auch diese Abhängigkeiten ausdrücken können. Ein Beispiel für solche Deployment-Artifakte liefert Apple.
Deployment von Anwendungen über den App Store
 Apple liefert pro Sekunde mehr als 800 Apps über den App Store aus (Quelle). Apple-typisch lädt man sich eine Anwendung herunter und nach einem Klick auf das Icon läuft die Anwendung immer sofort, ohne das der Benutzer noch irgend etwas machen muss.
Apple liefert pro Sekunde mehr als 800 Apps über den App Store aus (Quelle). Apple-typisch lädt man sich eine Anwendung herunter und nach einem Klick auf das Icon läuft die Anwendung immer sofort, ohne das der Benutzer noch irgend etwas machen muss.
Apple löst die Herausforderung eine Anwendung auszuliefern mit dem sogenannten Application Bundle. Native Mac OS X Applikationen sind mehr als nur eine einfache ausführbare Datei, auch wenn ein Benutzer im Finder immer nur ein einzelnes Ic on sieht. Unter Mac OS X besteht eine Applikation Bundle aus einer Verzeichnisstruktur, die sowohl die ausführbaren Dateien als auch alle benötigen Ressourcen enthält, die von einer Applikation benötigt werden. Diese Struktur ist von Apple genau definiert.
on sieht. Unter Mac OS X besteht eine Applikation Bundle aus einer Verzeichnisstruktur, die sowohl die ausführbaren Dateien als auch alle benötigen Ressourcen enthält, die von einer Applikation benötigt werden. Diese Struktur ist von Apple genau definiert.
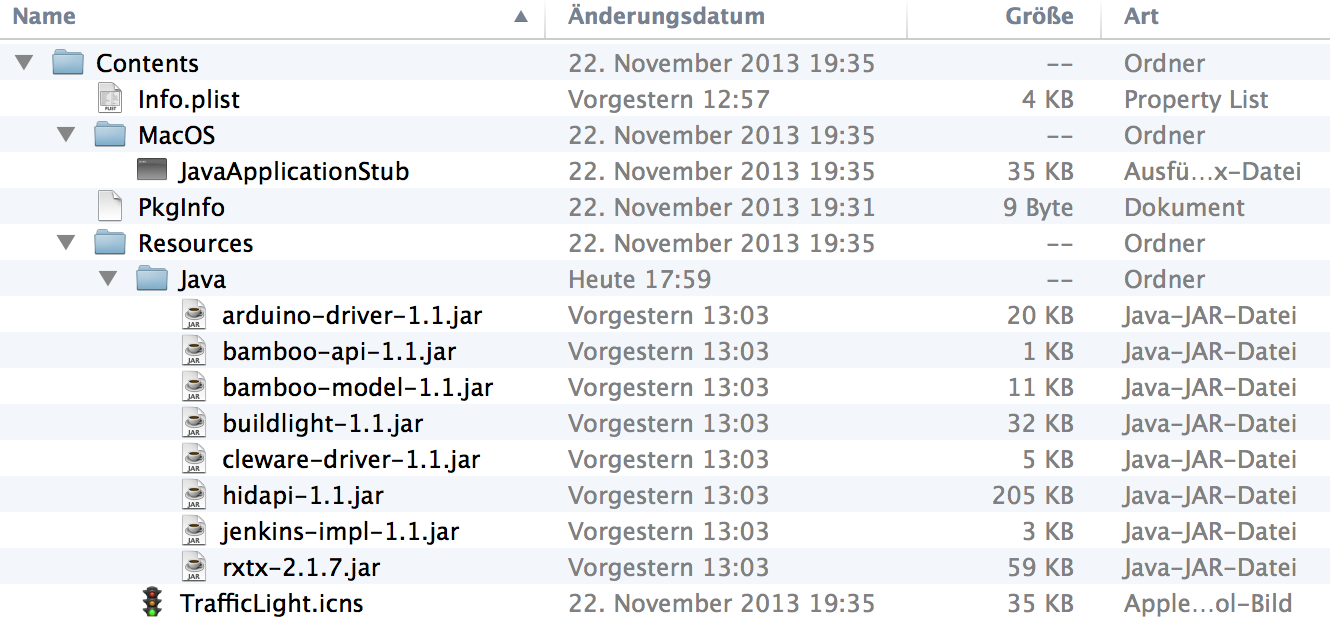
Ein Application Bundle enthält die folgenden Verzeichnisse und Dateien:
- Eine Info.plist Datei im Contents Verzeichnis, die wichtige Meta-Informationen enthält, die von Mac OS X benutzt werden, um die Anwendung zu starten. (“Java Dictionary Info.plist Keys”)
- Außerdem sollte eine Datei mit dem Namen PkgInfo in dem Contents Verzeichnis enthalten sein. (“Data Type Registration”)
- Die Icons, die im Dock und im Finder angezeigt werden, befinden sich im Resources Verzeichnis.
- Im Resources Verzeichnis werden außerdem Dateien abgelegt, die für die Ausführung benötigt werden.
- Im MacOS Verzeichnis befinden sich die ausführbaren Dateien.
Wenn man eine Anwendung im App Store veröffentlichen möchte, müssen alle Ressourcen, die von der Anwendung benötigt werden mit der Anwendung ausgeliefert werden. Ansonsten wird die Anwendung von Apple abgelehnt und kann nicht veröffentlich werden. Dieses Konzept scheint sich wunderbar zu eignen um einen Microservice auszuliefern. Meistens hat man in Produktion aber keine Apple Server. Deshalb wäre es wünschenswert ein alternativ Konzept dafür zu haben. Häufig werden Webanwendungen auf einen Linux-Server ausgeliefert. Daher hat die Anwendung noch eine zusätzliche Abhängigkeit zu Infrastruktur und diese Abhängigkeit kann man benutzen, um die Anwendung auszuliefern.
Linux-Paketverwaltung
Die meisten Linux Distributionen verfügen über eine Software-Paketverwaltung. Eine Software-Paketverwaltung ermöglicht die komfortable Verwaltung von Software, die in Paketform vorliegt. Dazu gehören das Installieren, Aktualisieren und Deinstallieren der Software.
Voraussetzung für Paket-Management ist, dass die zu installierende Software als entsprechendes Paket vorliegt. Ein solches Paket wird meistens von einem Betriebssystemanbieter erstellt, angeboten und gepflegt. Software wird meistens verteilt in unterschiedlichen Verzeichnissen des System installiert. Diese Verzeichnisse sind im Filesystem Hierarchy Standard definiert.
Änderungen, welche die Paketverwaltung zur Installation des Pakets am System vornehmen muss, werden von der Paketverwaltung aus dem Paket ausgelesen und umgesetzt. Erkennt die Paketverwaltung dabei, dass noch weitere Software für das Funktionieren benötigt wird (sogenannte Abhängigkeit, z. B. eine Programmbibliothek), aber noch nicht installiert ist, warnt sie entweder oder versucht, die fehlende Software mit den ihr zur Verfügung stehenden Mitteln, z. B. aus einem Repository, nachzuladen und vorweg zu installieren.
Konkrete Beispiele für Programme um Software-Pakete zu installieren sind:
- Das Programm RPM, dass Pakete vom Typ *.rpm installieren und löschen kann und
- das Programm Dpkg, dass Pakete vom Typ *.deb installieren und löschen kann.
Beide können aber keine Abhängigkeiten auflösen, da sie keine Funktionen haben, um Software nachzuladen. Dies können höhere Schichten der Paketverwaltungen wie YUM, APT, pkg-get und andere. Mit YUM oder APT ist es aber somit möglich auch die Abhängigkeiten zwischen Anwendungsserver und Anwendung aus zu drücken. Da ich häufig Ubuntu verwende und ich deshalb mit Deb-Paketen besser vertraut bin, möchte ich diese im folgenden Besprechen. Die Konzepte für Rpm-Pakete sind allerdings ähnlich.
Aufbau ein Deb-Paket
Jedes Deb-Paket besteht aus drei Dateien, die mittels des UNIX-Kommandos ar oder dem debianspezifischen Kommando dpkg-deb entpackt werden können:
- debian-binary: eine Textdatei mit der Versionsnummer des verwendeten Paketformats.
- control.tar.gz: ein gepacktes Archiv, dass Dateien enthält, die zur Installation dienen oder Abhängigkeiten auflisten. Hier werden nur ein paar Beispiele aufgeführt. Weiterführende Beschreibungen dazu finden sich z. B. in der Offiziellen Debian FAQ zu .deb Paketen.
- control enthält eine Kurzbeschreibung des Paketes sowie weitere Informationen, wie dessen Abhängigkeiten.
- md5sums enthält MD5-Prüfsummen aller im Paket enthaltenen Dateien, um Verfälschungen erkennen zu können.
- conffiles listet die Dateien des Paketes auf, die als Konfigurationsdateien behandelt werden sollen.
- preinst, postinst, prerm, postrm sind optionale Skripte, die vor oder nach dem Installieren, Aktualisieren oder Entfernen des Pakets ausgeführt werden. Sie werden mit den Rechten des Nutzers root ausgeführt.
- data.* Ist ein mit komprimiertes Archiv und enthält die eigentlichen Programmdaten mit relativen, beim Stammverzeichnis beginnenden Pfaden.
Integration in das Buildsystem
Mit jdeb gibt es eine Bibliothek, die einen Ant task und ein Maven Plugin bereitstellt um Debian Pakete zu erstellen. Diese Bibliothek ist Plattform unabhängig und baut Debian Pakete ohne die Installation von irgendwelchen zusätzlichen Tools.
Natürlich gibt es auch ein Gradle-Plugin das Debian Pakete baut. Das Plugin basiert auch auf jdeb und stellt eine Brücke zwischen jdeb und Gradle dar. Das folgende Listing zeigt die Verwendung des Plugins zusammen mit dem Application Plugin:
apply plugin: 'application'
apply plugin: 'pkg-debian'
debian {
packagename = "product"
publications = ['mavenStuff']
controlDirectory = "${projectDir}/debian/control"
changelogFile = "${projectDir}/debian/changelog"
outputFile = "${buildDir}/debian/${packagename}_${version}.deb"
data {
dir {
name = "${projectDir}/debian/data"
exclusions = ["**/.DS_Store", "changelog"]
}
dir {
name = "${buildDir}/debian-data/"
exclusions = ["**/.DS_Store"]
}
file {
name = "${projectDir}/src/main/resources/application.conf"
target = "etc/product/application.conf"
mapper {
fileMode = "755"
}
}
}
}
task prepareDeb {
dependsOn installApp
copy {
from "${buildDir}/install/"
into "${buildDir}/debian-data/usr/share/"
}
}
Zusammenfassung
Die Microservices-Bewegung erscheint auf den ersten Blick, wie das reaktive Manifest der Fachabteilung. Durch das parallele Bearbeiten von Fachlichkeiten kann das vorher monolithische Deployment von Anwendungen parallelisiert werden und die IT Abteilung schneller liefern. Dadurch erzeugt man aber eine Vielzahl an Deployment-Artifakten, die gemanagt werden müssen. Häufig ist ein monolithisches Deployment aber schon schwer genug. Da sehr viele Abhängigkeiten existieren. Sehr oft werden Anwendungen auf Linuxsystemen ausgeliefert. Diese Abhängigkeit zur Infrastruktur kann man aber auch ausnutzen, in dem man die Paketverwaltung der Linuxsysteme nutzt, um die Anwendungen auszuliefern, man baut dann nicht einfach nur ein Web Archive (WAR Dateien), sondern liefert ein Linux-Paket aus, darin ist alles enthalten, was ein Dienst benötigt, um ordnungsgemäß ausgeführt werden zu können. Die Paketverwaltung löst dann alle Abhängigkeiten auf, damit eine Anwendung/Dienst läuft und führt alle nötigen Schritte zur Installation der Software automatisiert aus. Damit erhält man auf den Linuxsystemen ein Apple ähnliches Deployment und kann sich eine Art App Store in Form eines Repository aufbauen, das die Auslieferung von Software stark vereinfach. Theoretisch ist durch dieses Vorgehen möglich seinen kompletten IT-Stack einfach nur mit einen Befehl auszuliefern , führt man z.B. „apt-get upgrade“ aus, werden alle Pakete wenn möglich auf verbesserte Version aktualisiert.

Java Profiler – Marke Eigenbau mit Elasticsearch, Logstash und Kibana (ELK Stack)
In meinen Beitrag “OutOfMemoryError: Java Heapdump Analyse – Was tun? Wenn die Produktion spinnt!” werden verschiedene Werkzeuge genannt, mit denen man eine Java-Anwendung überwachen kann. VisualVM und JConsole sind hervorragende Werkzeuge, die einem Software Ingenieur Einblick in eine einzelne laufende Applikation geben.
VisualVM ermöglicht es zwar Snapshots von Anwendungsmetriken, wie Speicherverbrauch, CPU-Auslastung aufzunehmen, aber man muss diese Snapshots händisch erstellen, tut man das nicht sind alle Daten weg, wenn man VisualVM beendet. Außerdem muss VisualVM zur Aufzeichnung der Daten die ganzen Zeit parallel zur Anwendung laufen. Wenn VisualVM gerade nicht läuft, dann werden logischerweise auch keine Daten gesammelt. Meistens hat man in modernen Web-Architekturen auch nicht nur einen Anwendungsserver und gerade für die Überwachung und Aufzeichnung eines kompletten Clusters ist VisualVM nur bedingt geeignet, hier braucht man schnell kommerzielle Lösungen, wie AppDynamics oder NewRelic.

Abbildung 1: VisualVM – Laufzeitmetriken während eines Lasttests
Ein anderes Problem ist, dass man Laufzeitmetriken nur schwer mit Logdaten korrelieren kann, da es für unterschiedliche Probleme in den meisten Unternehmen auch unterschiedliche Lösungen gibt, z.B. NewRelic zum Aufzeichnen von Laufzeitmetriken einer Anwendung und Splunk für die Logdateianalyse. Man muss also ständig zwischen den unterschiedlichen Software-Lösungen hin und her springen und ist selbst dafür verantwortlich seine Zeiteinstellungen in beiden Anwendungen zu synchronisieren, was bei komplexeren Zeitreihenanalysen lästig ist. Somit kann es schwer fallen das Zugriffsprotokoll mit dem Ansteigen des Speichers oder der CPU-Auslastung in Beziehung zu bringen. Gerade bei plötzlich auftretenden java.lang.OutOfMemoryError wäre es wünschenswert, wenn man Laufzeitmetriken mit den Aktivitäten auf der Webseite korrelieren könnte.
Daraus ergeben sich die folgenden funktionalen Anforderungen an eine Software Lösung zur Laufzeit-Überwachung einer Anwendung:
- Laufzeitdaten einer Anwendung sollen kontinuierlich automatisch gesammelt werden,
- Logdaten sollen ebenfalls automatisch kontinuierlich gesammelt werden,
- Laufzeitdaten und Logdaten von mehren Server müssen korreliert werden können.
Im meinem letzten Beitrag „Splunk – Marke Eigenbau mit Elasticsearch, Logstash und Kibana (ELK Stack)“ wird der ELK Stack vorgestellt, um Logdaten sammeln und analysieren zu können. Mit Kibana werden die gesammelten Logdaten visualisiert und ausgewertet. Eine interessante Frage ist nun: Kann man den ELK Stack auch benutzen, um seine Java-Anwendung zu überwachen. Dann wären alle drei Anforderungen an Software-Lösung zur Laufzeit-Überwachung einer Anwendung auf einen Schlag erfüllt.
Die Frage, ob man den ELK Stack auch zum Überwachen von Java-Anwendungen benutzen kann, wird in diesem Beitrag beantwortet, in dem wir einen einfachen Java-Profiler bauen, der auf dem ELK Stack basiert. Ziel ist es den Speicherverbrauch eines Anwendungsserver-Cluster mit dem ELK Stack zu überwachen und mit Logdaten korrelieren zu können. Betrachten wir also zunächst, welche Möglichkeiten in der Java-Laufzeitumgebung existieren, um das Laufzeitverhalten von Software zu messen.
so true! just great! „@theagilepirate: Genius at #xp2014 lightning talks. No further comment needed 😀 pic.twitter.com/mA8v57eBwx“
— Uwe Friedrichsen (@ufried) 28. Mai 2014
Java Profiling
Profiler sind Werkzeuge, mit denen sich das Laufzeitverhalten von Software analysieren lässt. Es gibt unterschiedliche Problembereiche in der Softwareentwicklung, die durch ineffiziente Programmierung ausgelöst werden. Ein Profiler hilft einem Software Ingenieur durch Analyse und Vergleich von laufenden Programmen die verschiedensten Problembereiche aufzudecken. Daraus kann man Maßnahmen zur strukturellen und algorithmischen Verbesserung des Quellcodes ableiten. Beispielsweise kann das Ziel eines Profiling das Aufspüren von Performance-Bottenecks oder eines Memory-Leaks sein, die anschließend beseitigt werden müssen.
Die JVM ist der Teil der Java-Laufzeitumgebung, der für die Ausführung des Bytecodes verantwortlich ist. Während der Bytecode-Ausführung gibt es bestimmte Laufzeitmetriken, die gemessen werden können. Beispiele für Laufzeitmetriken sind der Speicherverbrauch, die Anzahl von laufenden Threads oder die CPU Auslastung.
Abbildung 2 zeigt die Java Memory Architektur der Oracle HotSpot Implementierung der JVM und die JVM-Parameter, mit denen man die Speicherverwaltung beeinflussen kann. Young und Old Generation bilden zusammen den Heap. Daneben steht die Permanent Generation, die man seit JDK8 auch Metaspace nennt. In allen genannten Bereichen kann der Speicher ausgehen, schließlich handelt es sich dabei um eine physikalisch begrenzte Größe. Geht der Speicher in Heap oder Metaspace aus, dann kommt es zum sogenannten OutOfMemoryError.
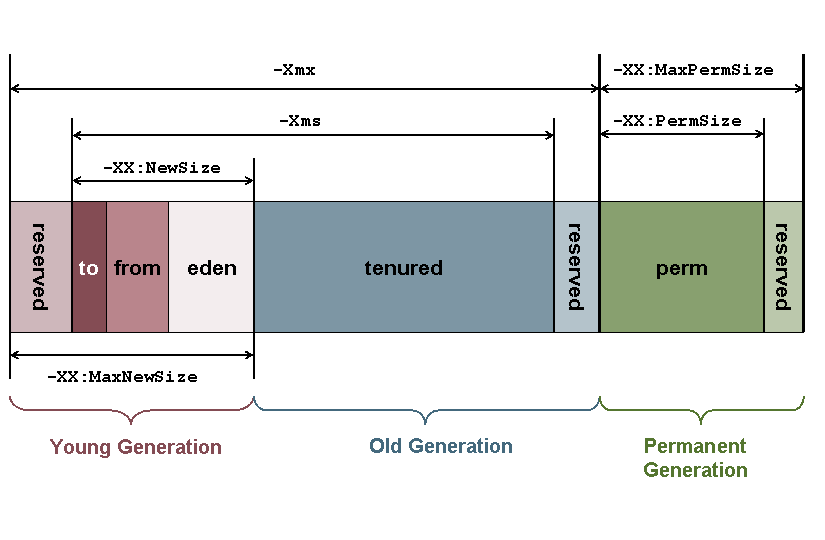
In der Java-Welt gibt es die folgenden beiden Spezifikationen, die sich u.a. damit beschäftigen die Java Memory Architektur zu überwachen können: JSR-174: Monitoring and Management Specification for the Java Virtual Machine und JSR-163: Java Platform Profiling Architecture. JSR-174 definiert Anforderungen an ein JVM Monitoring- und Managementsystem. Der JSR-163 definiert nicht nur Schnittstellen, die von JSR-174 benötigt werden, sondern stellt auch Referenz-Implementierungen und Test-Werkzeuge bereit, um Java-Anwendungen überwachen, fern steuern und messen zu können. Seit JDK5 sind die beiden JSRs in der Laufzeitumgebung integriert (Quelle). Beispiele für eine Schnittstelle und Referenz-Implementierung zur Überwachung der Java Memory Architektur sind die Schnittstelle java.lang.management.MemoryPoolMXBean und die Klasse java.lang.management.MemoryUsage.
Die JVM besitzt eine automatische Speicherverwaltung und benutzt den Heap zum Allokieren von neuen Objekten, der wiederum aus mehreren Speicherbereichen besteht. Außerdem besitzt die JVM den sogenannten Non-Heap Memory in dem sich das sogenannte Method Area befindet, in dem sich die geladenen Klassen befinden. Daraus resultieren mehre Memory Pools. Ein Instanz der Management-Schnittstelle MemoryPoolMXBean repräsentiert also immer einen spezifischen Memory Pool, wie z.B Old Generation oder Eden Space. In Oracle HotSpot Implementierung findet man alle in Abbildung 2 dargestellten Memory Pools wieder. Auf alle Instanzen (sun.management.MemoryPoolImpl) der unterschiedlichen Memory Pools kann man mit der ManagementFactory.getMemoryPoolMXBeans() zugreifen.
Mit der Methode getUsage() bekommt man die geschätzte Speichergröße des aktuellen Memory Pools. Für einen Memory Pool, der vom einem Garbage Collector bereinigt wird, gilt das die Speichergröße sowohl reachable als auch unreachable Objekte beinhaltet.
Die Klasse MemoryUsage beinhaltet die folgenden vier Werte:
| Wert | Beschreibung |
|---|---|
| init | repräsentiert die initiale Speichermenge in bytes, die während des Startvorgangs der JVM allokiert wird. Dieser Wert kann auch undefined sein. |
| used | repräsentiert den aktuellen Speicherverbrauch in bytes. |
| committed | repräsentiert den maximalen Speicherverbrauch, der von der JVM ohne Speicherumstrukturierung garantiert wird. Dieser Wert kann sich über die Laufzeit hinweg ändern. |
| max | repräsentiert maximalen Speicherverbrauch, der von der JVM allokiert werden kann. |
Ähnliche Management-Beans gibt es auch zum Abfragen von anderen Laufzeitmetriken, wie Anzahl an laufenden Threads oder geladenen Klassen. Laufzeitmetriken, die nicht in der java.lang.management API enthalten ist, kann man selbst implementieren. Dazu gibt es die java.lang.instrument API, damit ist es z.B. auch möglich die Laufzeit von Methoden zu messen, in dem man den Bytecode eine Klasse verändert. Dazu verwendet man einen sogenannten Java-Agenten. Diese API ist die Grundlage für viele kommerzielle Profiler und wird üblicherweise als JAR-Datei aufgeliefert. Das folgende Listig zeigt einen Java-Agenten und wie man den Bytecode einer Klasse mit Javassist umschreiben kann, um nach jeden Methoden-Aufruf die Ausführungzeit der Methode in der Konsole ausgegeben wird:
public class AppStashAgent {
public static void premain(String agentArguments, Instrumentation instrumentation) {
instrumentation.addTransformer(new ClassFileTransformer() {
@Override
public byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException {
byte[] result = new byte[0];
try {
String dotClassName = className.replace('/', '.');
ClassPool cp = ClassPool.getDefault();
CtClass ctClazz = cp.get(dotClassName);
for (CtMethod method1 : ctClazz.getDeclaredMethods()) {
method1.addLocalVariable("elapsedTime", CtClass.longType);
method1.insertBefore("elapsedTime = System.nanoTime();");
method1.insertAfter(" { elapsedTime = System.nanoTime() - elapsedTime; "
+ "System.out.println(\" Method elapsedTime = \" + elapsedTime);}");
result = ctClazz.toBytecode();
}
} catch (Throwable e) {
e.printStackTrace();
}
return result;
}
});
}
}
Die meisten Java-Profiler geben zwar einen detaillierten Einblick in eine Anwendung. Es kann aber vorkommen, dass man einen Profiler nicht produktiv Betrieb benutzen kann. Das kann daran liegen, dass dieser Profiler entweder das Java Virtual Machine Profiling Interface (JVMPI) oder das Java Virtual Machine Tool Interface (JVMTI) zum Sammeln von Daten benutzt. Die Verwendung der JVMPI oder JVMTI kann dazu führen, dass sich die Ausführungszeit der Anwendung verlangsamt.
In diesem Fall erzwingt das Vorhandensein eines Agenten, dass der gesamte Bytecode einer Klasse immer von der Festplatte geladen wird, da der Bytecode nach dem Laden der Klasse verändert wird. Um einen solchen Profiler trotzdem benutzen zu können, muss man aufwändig produktionsnahe Lastsenarien mit Lasttest-Werkzeugen wie JMeter oder Gatling simulieren.
Eine Alternative zum klassischen Profiling ist die manuelle Messung der Ausführungszeit im Quellcode, die in eine Logdatei geschrieben wird. Abhängig von der Größe des Entwicklungsteams und Anwendung kann das Schnell zum Wartungsalptraum werden, da man den Quellcode mit dem Messcode verschmutzt. Um den Quellcode nicht zu verschmutzen, existieren Frameworks wie JETM. JETM betrachten wir im Folgenden, um ein besseres Verständnis darüber zu bekommen, welche Möglichkeiten und Konzepte existieren, um eine Anwendung alternativ als mit einem Agenten zu messen.
Java Execution Time Measurement Library (JETM)
Mit Java Execution Time Measurement Library (JETM) kann ein Software Ingenieur die Ausführungsgeschwindigkeit seiner Anwendung bis auf Methoden-Ebene messen. In einer Spring-Anwendungen kann mit JETM die Ausführungsgeschwindigkeit sogar messen werden, ohne eine Zeile Quellcode anzufassen. JETM benutzt dann Spring AOP und generiert dynamische Proxies zum Messen der Spring-Beans. JETM ist sehr einfach zu benutzen, man muss nur die JETM-JARs auf dem ClassPath packen und die Konfiguration der Anwendung entsprechend anpassen. Das folgende Listing zeigt, was man in der web.xml einer Web-Anwendung konfigurieren muss, um mit JETM die einzelnen Requests einer Anwendung zu messen.
<servlet>
<servlet-name>performanceMonitor</servlet-name>
<servlet-class>etm.contrib.integration.spring.web.SpringHttpConsoleServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>performanceMonitor</servlet-name>
<url-pattern>/performance/*</url-pattern>
</servlet-mapping>
<filter>
<filter-name>performance-monitor</filter-name>
<filter-class>
etm.contrib.integration.spring.web.SpringHttpRequestPerformanceFilter
</filter-class>
</filter>
<filter-mapping>
<filter-name>performance-monitor</filter-name>
<url-pattern>*</url-pattern>
</filter-mapping>
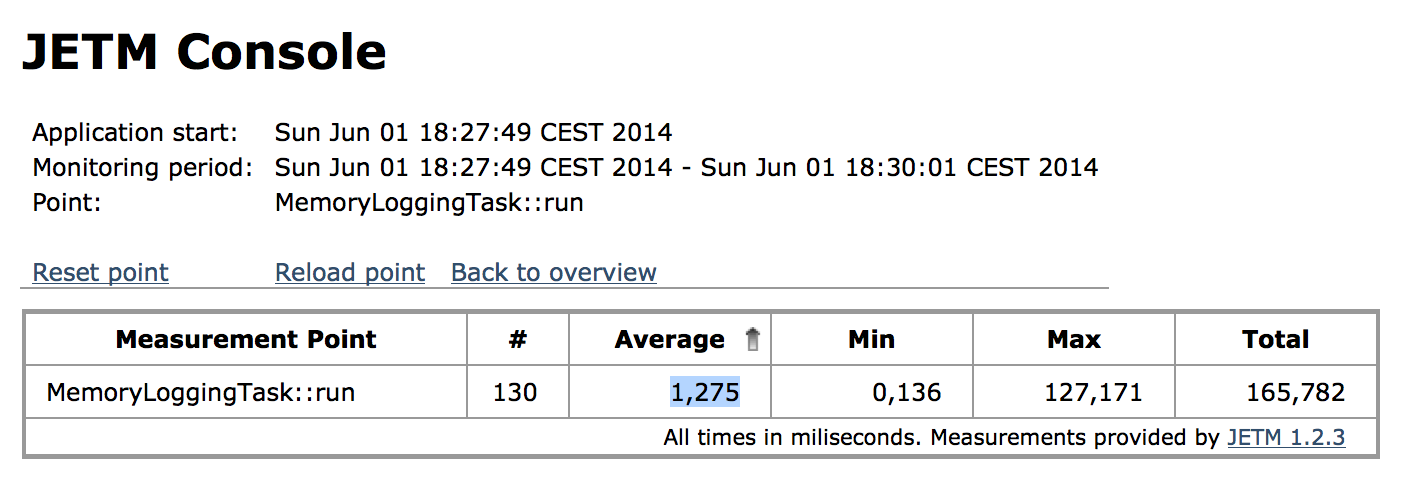
Die sogenannte JETM Console macht die Ergebnisse der Messungen verfügbar. In Abbildung 3 ist ein Bildschirmfoto der JETM Konsole zu sehen. Die JETM Console kann man entweder über ein Servlet in eine bestehende Web-Anwenundung integrieren werden oder man benutzt einen Standalone HTTP Console Server. Damit kann JETM sowohl für Macrobenchmarks als auch für Microbenchmarks benutzt werden.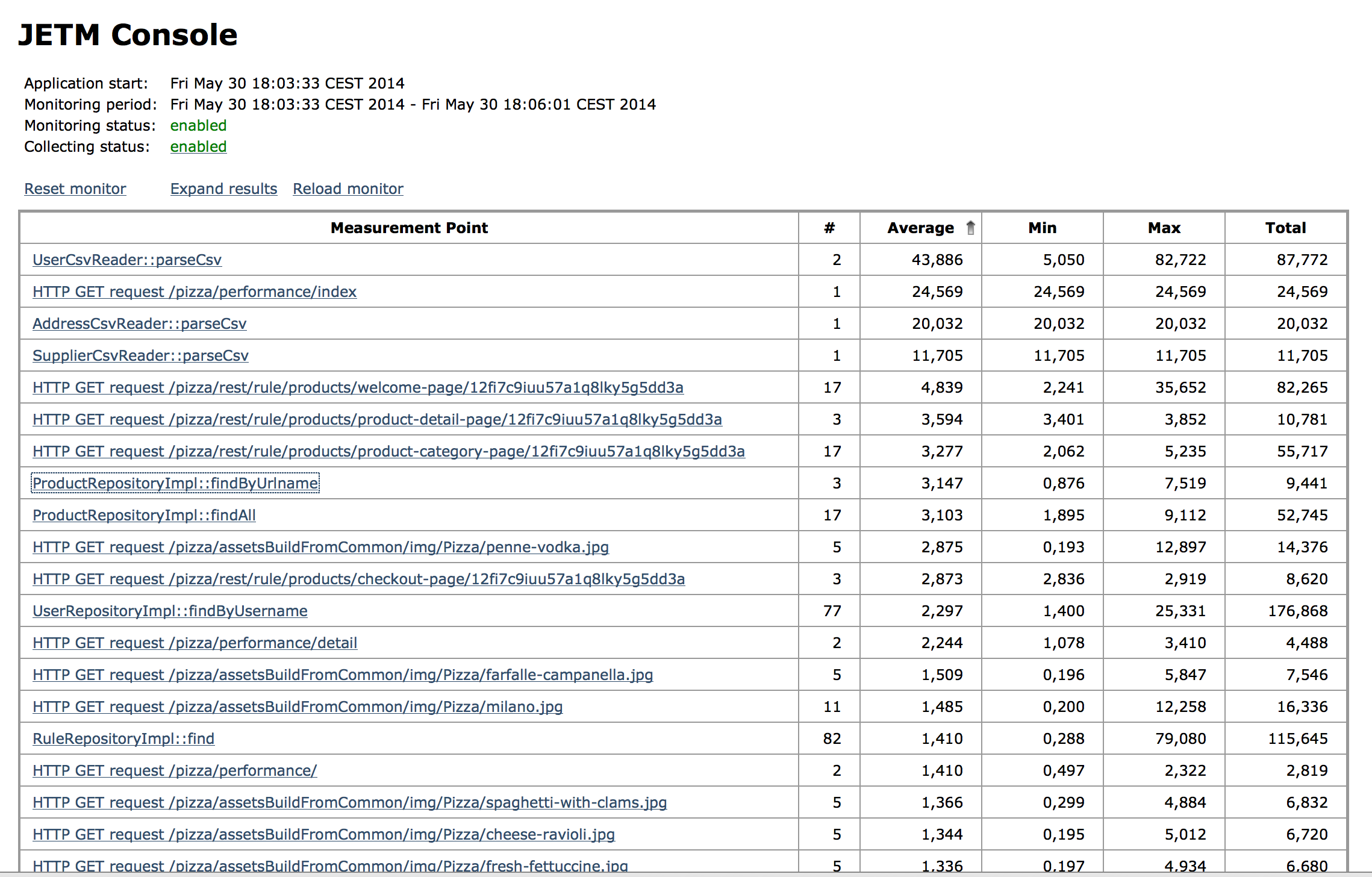
Abbildung 3: JETM Console
Aus den Betrachtungen über die java.lang.management, java.lang.instrument API und JETM ergeben sich noch zwei nicht funktionale Anforderungen an eine Software-Lösung zur Laufzeit-Überwachung einer Java-Anwendung:
- Laufzeitdaten müssen auch in Produktion gesammelt werden können,
- Das Sammeln von Laufzeitmetriken sollte über Konfiguration gestartet werden.
Betrachten wir nun im Folgenden, wie wir aus den definierten funktionalen und nicht-funktionalen Anforderungen ein Minimum Viable Product einer Software-Lösung zur Laufzeit-Überwachung bauen können.
Profiler auf ELK Stack Basis
Wie bereits erwähnt, ergeben sich die folgenden funktionalen und nicht-funktionalen Anforderungen an eine Software-Lösung zur Laufzeit-Überwachung einer Anwendung:
- Laufzeitdaten einer Anwendung sollen kontinuierlich automatisch gesammelt werden,
- Logdaten sollen ebenfalls automatisch kontinuierlich gesammelt werden,
- Laufzeitdaten und Logdaten von mehren Server müssen korreliert werden können,
- Laufzeitdaten müssen auch in Produktion gesammelt werden können,
- Das Sammeln von Laufzeitmetriken sollte über Konfiguration gestartet werden.
Der ELK Stack ermöglicht es Logdaten automatisch zu sammeln und besteht aus den folgenden Komponenten:
- Elasticsearch – für die Suche und Datenanalyse,
- Logstash – zum Zentralisieren, Anreichern und Parsen von Logdaten,
- Kibana – für die Daten Visualisierung.
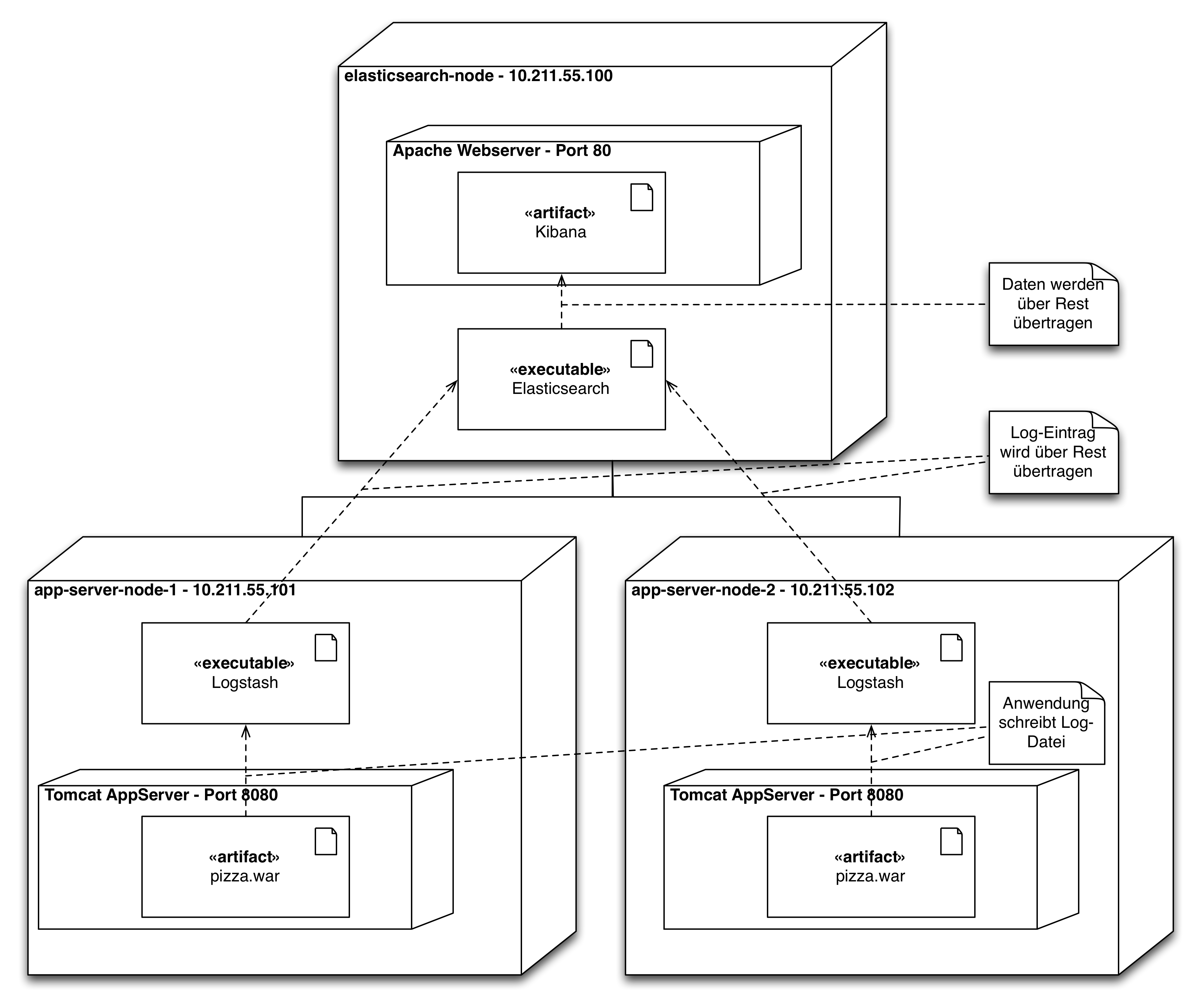
Abbildung 4 zeigt einen möglichen architektonischen Aufbau eines ELK Clusters. Das Cluster besteht aus drei Rechnern. Auf zwei Rechner sind Tomcat-Anwendungserver installiert. Von den Tomcat-Anwendungserver werden kontinuierlich Logdaten schreiben. Auf diesen beiden Rechnern ist deshalb ausserdem Logstash installiert. Logstash wirkt in der Installation als ETL-Tool und extrahiert die Logdaten, transformiert sie ggf., sodass die Logdaten in Elasticsearch geschrieben und von Elasticsearch indexiert werden können. Auf einem dritten Rechner ist ein Apache Webserver installiert, der als Webverzeichnis für Kibana dient, dass die von Logstash gesammelten Logdaten der beiden Tomcat-Anwendungsserver visualisiert. Für die Visualisierung nutzt Kibana die Rest-API von Elasticsearch.
Log = Timestamp + Data
Die Logdaten einer Anwendung bestehen immer aus einem Zeitstempel und irgendwelchen Daten. Die Laufzeitmetriken unserer Anwendung haben einen ähnlichen Aufbau. Zu einem bestimmten Zeitpunkt wird von der Anwendung eine bestimmte Menge des Speichers konsumiert.
Man kann sich die JVM, wie eine echte Maschine vorstellen, die mit Sensoren bestückt ist, diese Sensoren können periodisch zur Überwachung abgefragt werden. Ein solcher Sensor ist z.B. eine MemoryPoolMXBean-Instanz. Wenn man diese Sensordaten in eine Form bringt, die noch über einen Zeitstempel verfügt und in eine Datei schreibt, können die Logdaten von Logstash verarbeitet und in Elasticsearch überführen werden. Das folgende Listing zeigt eine mögliche JSON Struktur für unseren Speichersensor:
{
"name": "PS Old Gen",
"type": "Heap memory",
"@timestamp": "2014-05-28T23:43:19",
"@version": "1",
"init": 266862592,
"used": 2417592,
"committed": 266862592,
"max": 2863661056
}
Damit ist der ELK Stack schonmal in der Lage unsere funktionalen Anforderungen an eine Software-Lösung zur Laufzeit-Überwachung einer Anwendung zu erfüllen. Wir haben aber noch nicht-funktionale Anforderungen definiert, u.a sollen die Laufzeitmetriken auch produktiv gesammelt werden können und das Sammeln über Konfiguration gestartet werden. Um losgelöst von Rest der Anwendung Laufzeitmetriken sammeln, bietet sich ein Runnable an. Ein Runnable kann über den ScheduledThreadPoolExecutor immer im einem Hintergrund der Anwendung laufen und kontinuierlich Laufzeitmetriken sammeln. Denn ScheduledThreadPoolExecutor kann man mit Spring einfach konfigurieren, wie wir später sehen werden. Das folgende Listing zeigt, wie man die MemoryUsage Werte der unterschiedlichen MemoryPoolMXBean in der Konsole im JSON-Format weglassen kann:
public class MemoryLoggingTask implements Runnable {
private static final Logger LOGGER = LoggerFactory.getLogger(MemoryLoggingTask.class);
private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
@Override
public void run() {
for (MemoryPoolMXBean memoryPoolMXBean : ManagementFactory.getMemoryPoolMXBeans()) {
try {
String message = memoryUsageAsJsonString(memoryPoolMXBean);
LOGGER.info(message);
} catch (IOException e) {
LOGGER.error("Object could not converted to JSON String:", e);
}
}
}
private String memoryUsageAsJsonString(MemoryPoolMXBean memoryPoolMXBean) throws IOException {
return OBJECT_MAPPER.writeValueAsString(buildMemoryUsageInfo(memoryPoolMXBean));
}
private MemoryUsageInfo buildMemoryUsageInfo(MemoryPoolMXBean memoryPoolMXBean) {
return MemoryUsageInfo.builder()
.name(memoryPoolMXBean.getName())
.type(memoryPoolMXBean.getType().toString())
.usage(memoryPoolMXBean.getUsage())
.build();
}
}
Die Frage ist nun: Ist unser MemoryLoggingTask schnell genug für den produktiven Einsatz? Abbildung 5 zeigt einen Microbenchmark der run-Methode, der mit JETM aufgezeichnet wurden ist. Die Methode wurde 130 mal aufgerufen und die Ausführungszeit braucht im Mittel 1ms. Was man in der Abbildung nicht sieht, ist das der Maximalwert bei ersten Aufruf erfolgt ist. Bei jeden weiteren Methoden wird ungefähr 150ns für die Ausführung benötigt. Damit spricht nichts gegen den produktiven Einsatz des MemoryLoggingTask.
Die letzte nicht-funktionale Anforderung ist, dass das Sammeln von Laufzeitmetriken über Konfiguration gestartet werden sollte. Wie schon erwähnt, ist es mit Spring sehr einfach unseren MemoryLoggingTask im Hintergrund laufen zulassen. Das folgende Listing zeigt, was man dazu machen muss.
<bean id="appStashMemoryLogging" class="io.github.appstash.task.MemoryLoggingTask" />
<task:scheduled-tasks scheduler="appStashScheduler">
<task:scheduled ref="appStashMemoryLogging" method="run" fixed-delay="1000"/>
</task:scheduled-tasks>
<task:scheduler id="appStashScheduler" pool-size="10"/>
Zusammenfassung
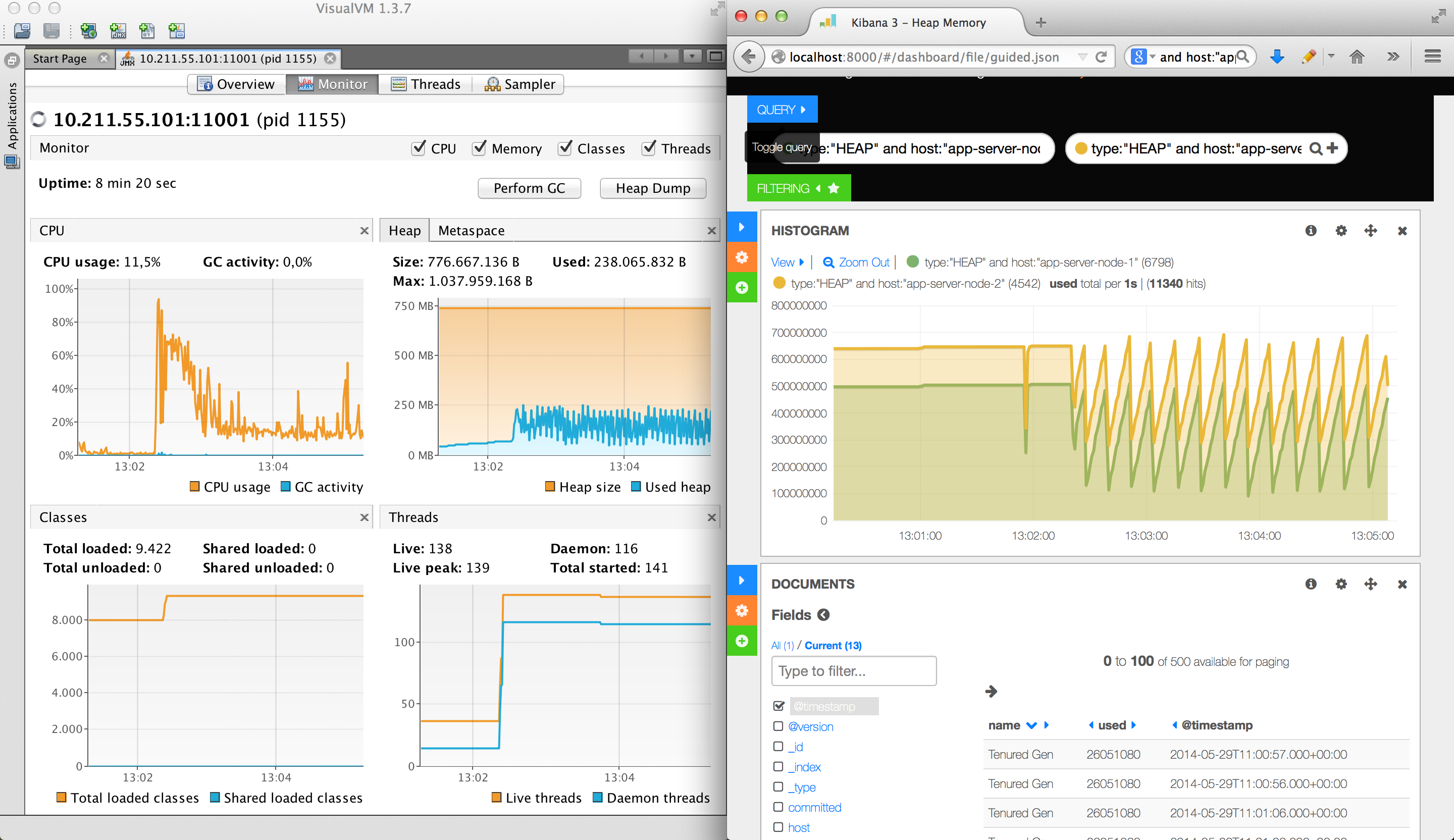
Wie haben in diesen Beitrag gesehen, dass man sich mit einfachsten Mitteln einen Profiler selber schreiben kann. Da Laufzeitmetriken auch als Zeitstempel mit Daten gesehen werden können, kann man diese Daten in eine Datei schreiben und mit einem Loganalysewerkzeug visualisieren. Abbildung 6 zeigt die Kibana Visualisierung vom Heap-Speicher neben VisualVM. Deutlich zu erkennen ist die kontinuierliche Garage Collection des Heaps. Natürlich kann man das gleiche Konzept auch mit anderen Loganalysewerkzeugen, wie z.B. Splunk nutzen, um ähnliche Visualisierungen herzustellen.
Um den kompletten Cluster, der in Abbildung 4 dargestellt ist, zu starten, muss man nur VirtualBox und Vagrant installieren. Danach kann man nur die folgenden drei Befehle ausführen. Das in Abbildung 6 dargestellte Dashbord befindet sich unter /appstash/external/Heap Memory Dashboard.
bernd@mbp ~$ git clone https://github.com/zutherb/AppStash.git appstash bernd@mbp ~$ git checkout elk-example bernd@mbp ~$ cd appstash/vagrant bernd@mbp ~$ vagrant up
Auf die inAbbildung 4 im dargestellten Komponenten des ELK Stacks kann man über die folgenden Port Forwardings zu greifen:
- Kibana – http://localhost:8000/
- Elasticsearch – http://localhost:9200/
- Applikation 1 – http://localhost:8080/pizza/
- Applikation 2 – http://localhost:8081/pizza/
Von Continuous Integration zu Continuous Delivery (Teil 1)
Continuous Delivery wird häufig als Weiterentwicklung von Continuous Integration angesehen. Die Idee einer Deployment Pipeline soll dabei helfen, den Schritt von Continous Integration zu Continuous Delivery zu vollziehen.
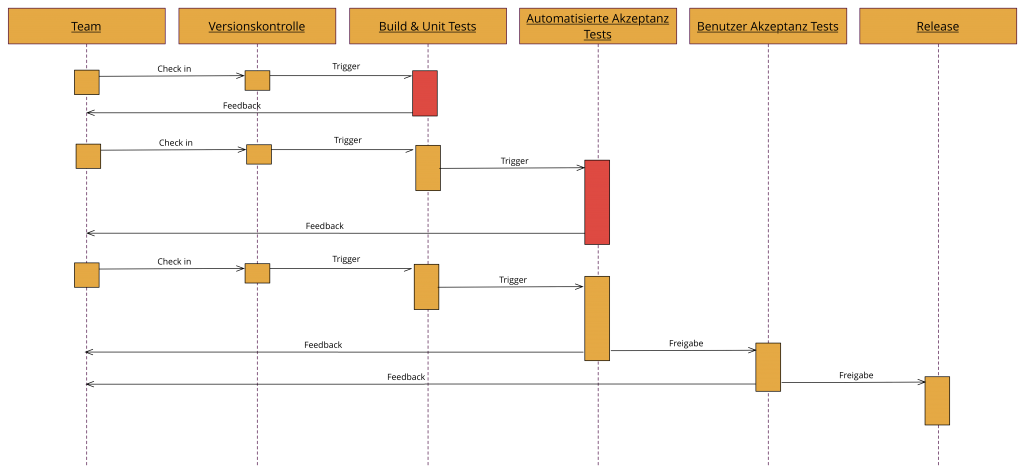
Abbildung 1 zeigt eine Deployment Pipeline. Den Anfang dieser Deployment Pipeline stellt das Entwicklungsteam dar, dass zusammen an einem Projekt arbeitet. Bei der Zusammenarbeit von mehreren Entwicklern kommt es häufig zu so genannten Integrationsfehler. Schlecht ist es, wenn diese Integrationsfehler erst spät entdeckt werden, denn in einer späten Projektphase ist die Beseitigung dieser Fehler deutlich teuer als in einer frühen Phase. Deshalb ist es wichtig, dass nach jeder Code-Integration ein automatisierter Build läuft, der zum Einen überprüft ob sich die Software überhaupt bauen lässt und zum Anderen die Software auf Fehler überprüft. Dabei hilft ein sogenanntes CI-System.
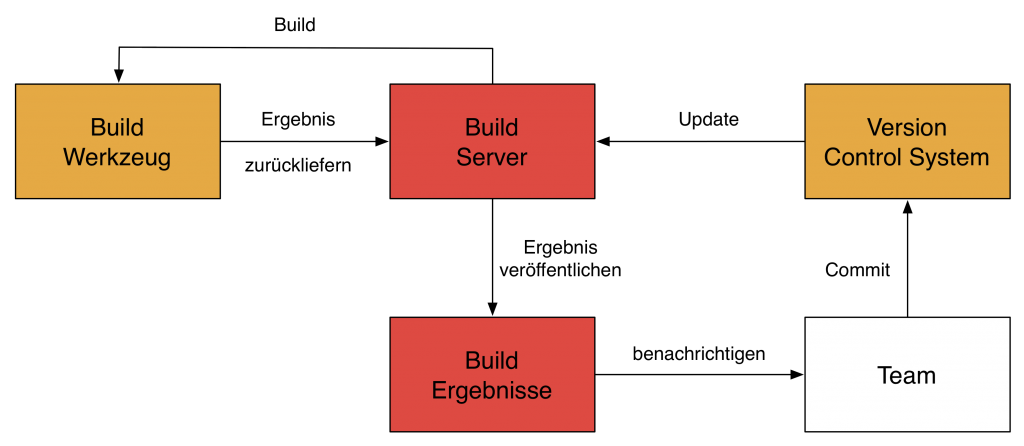
Abbildung 2 verdeutlich den schematischen Aufbau eines typischen CI-Systems und den Kreislauf der in einem CI-System vollzogen wird. Das Team führt Änderungen durch. Diese Änderungen werden vom Team an ein Version Control System (VCS) übergeben. Ein Build-Server überprüft kontinuierlich das VCS und führt bei Änderungen einen Build durch. Dieser Build kann erfolgreich sein oder fehlschlagen. Nach einem Build wird das Ergebnis vom Build-Server archiviert und das Ergebnis dem Entwicklungsteam mitgeteilt.
Der Schwerpunkt eines solchen CI Systems liegt also klar beim Entwickler. Dieser kann zufrieden sein, wenn der CI-Server signalisiert, dass der letzte Commit erfolgreich war. Leider wird dabei der Benutzer komplett außen vor gelassen, der mehr an neuer Funktionalität interessiert sein wird. Deshalb muss die Software im nächsten Schritt zum Benutzer kommen. Hierzu ist ein Release nötigt. Ein solches Release stellt in der Regel eine große Herausforderung da, denn dabei sind viele Beteiligte involviert und häufig auch viele manuelle Schritte, was zu einer hohen Fehlerrate führt. Leider vermeiden viele Unternehmen deshalb häufig Releases, was aus Sicht eines Benutzer natürlich ärgerlich ist, da er auf viele Features lange warten muss.
Als begeisterter Software-Entwickler und Consultant kann ich mit diesem Missstand natürlich nicht leben. Deshalb möchte ich euch im Verlauf der Zeit Techniken vorstellen, um neue Features zeitnah und fortwährend nach der Fertigstellung bereitzustellen. Damit werde ich euch zeigen, wie ich in meinem täglichen Alltag das Prinzip Continous Delivery zum Leben erwecken lasse.