In meinen Beitrag “OutOfMemoryError: Java Heapdump Analyse – Was tun? Wenn die Produktion spinnt!” werden verschiedene Werkzeuge genannt, mit denen man eine Java-Anwendung überwachen kann. VisualVM und JConsole sind hervorragende Werkzeuge, die einem Software Ingenieur Einblick in eine einzelne laufende Applikation geben.
VisualVM ermöglicht es zwar Snapshots von Anwendungsmetriken, wie Speicherverbrauch, CPU-Auslastung aufzunehmen, aber man muss diese Snapshots händisch erstellen, tut man das nicht sind alle Daten weg, wenn man VisualVM beendet. Außerdem muss VisualVM zur Aufzeichnung der Daten die ganzen Zeit parallel zur Anwendung laufen. Wenn VisualVM gerade nicht läuft, dann werden logischerweise auch keine Daten gesammelt. Meistens hat man in modernen Web-Architekturen auch nicht nur einen Anwendungsserver und gerade für die Überwachung und Aufzeichnung eines kompletten Clusters ist VisualVM nur bedingt geeignet, hier braucht man schnell kommerzielle Lösungen, wie AppDynamics oder NewRelic.

Abbildung 1: VisualVM – Laufzeitmetriken während eines Lasttests
Ein anderes Problem ist, dass man Laufzeitmetriken nur schwer mit Logdaten korrelieren kann, da es für unterschiedliche Probleme in den meisten Unternehmen auch unterschiedliche Lösungen gibt, z.B. NewRelic zum Aufzeichnen von Laufzeitmetriken einer Anwendung und Splunk für die Logdateianalyse. Man muss also ständig zwischen den unterschiedlichen Software-Lösungen hin und her springen und ist selbst dafür verantwortlich seine Zeiteinstellungen in beiden Anwendungen zu synchronisieren, was bei komplexeren Zeitreihenanalysen lästig ist. Somit kann es schwer fallen das Zugriffsprotokoll mit dem Ansteigen des Speichers oder der CPU-Auslastung in Beziehung zu bringen. Gerade bei plötzlich auftretenden java.lang.OutOfMemoryError wäre es wünschenswert, wenn man Laufzeitmetriken mit den Aktivitäten auf der Webseite korrelieren könnte.
Daraus ergeben sich die folgenden funktionalen Anforderungen an eine Software Lösung zur Laufzeit-Überwachung einer Anwendung:
- Laufzeitdaten einer Anwendung sollen kontinuierlich automatisch gesammelt werden,
- Logdaten sollen ebenfalls automatisch kontinuierlich gesammelt werden,
- Laufzeitdaten und Logdaten von mehren Server müssen korreliert werden können.
Im meinem letzten Beitrag „Splunk – Marke Eigenbau mit Elasticsearch, Logstash und Kibana (ELK Stack)“ wird der ELK Stack vorgestellt, um Logdaten sammeln und analysieren zu können. Mit Kibana werden die gesammelten Logdaten visualisiert und ausgewertet. Eine interessante Frage ist nun: Kann man den ELK Stack auch benutzen, um seine Java-Anwendung zu überwachen. Dann wären alle drei Anforderungen an Software-Lösung zur Laufzeit-Überwachung einer Anwendung auf einen Schlag erfüllt.
Die Frage, ob man den ELK Stack auch zum Überwachen von Java-Anwendungen benutzen kann, wird in diesem Beitrag beantwortet, in dem wir einen einfachen Java-Profiler bauen, der auf dem ELK Stack basiert. Ziel ist es den Speicherverbrauch eines Anwendungsserver-Cluster mit dem ELK Stack zu überwachen und mit Logdaten korrelieren zu können. Betrachten wir also zunächst, welche Möglichkeiten in der Java-Laufzeitumgebung existieren, um das Laufzeitverhalten von Software zu messen.
so true! just great! „@theagilepirate: Genius at #xp2014 lightning talks. No further comment needed 😀 pic.twitter.com/mA8v57eBwx“
— Uwe Friedrichsen (@ufried) 28. Mai 2014
Java Profiling
Profiler sind Werkzeuge, mit denen sich das Laufzeitverhalten von Software analysieren lässt. Es gibt unterschiedliche Problembereiche in der Softwareentwicklung, die durch ineffiziente Programmierung ausgelöst werden. Ein Profiler hilft einem Software Ingenieur durch Analyse und Vergleich von laufenden Programmen die verschiedensten Problembereiche aufzudecken. Daraus kann man Maßnahmen zur strukturellen und algorithmischen Verbesserung des Quellcodes ableiten. Beispielsweise kann das Ziel eines Profiling das Aufspüren von Performance-Bottenecks oder eines Memory-Leaks sein, die anschließend beseitigt werden müssen.
Die JVM ist der Teil der Java-Laufzeitumgebung, der für die Ausführung des Bytecodes verantwortlich ist. Während der Bytecode-Ausführung gibt es bestimmte Laufzeitmetriken, die gemessen werden können. Beispiele für Laufzeitmetriken sind der Speicherverbrauch, die Anzahl von laufenden Threads oder die CPU Auslastung.
Abbildung 2 zeigt die Java Memory Architektur der Oracle HotSpot Implementierung der JVM und die JVM-Parameter, mit denen man die Speicherverwaltung beeinflussen kann. Young und Old Generation bilden zusammen den Heap. Daneben steht die Permanent Generation, die man seit JDK8 auch Metaspace nennt. In allen genannten Bereichen kann der Speicher ausgehen, schließlich handelt es sich dabei um eine physikalisch begrenzte Größe. Geht der Speicher in Heap oder Metaspace aus, dann kommt es zum sogenannten OutOfMemoryError.
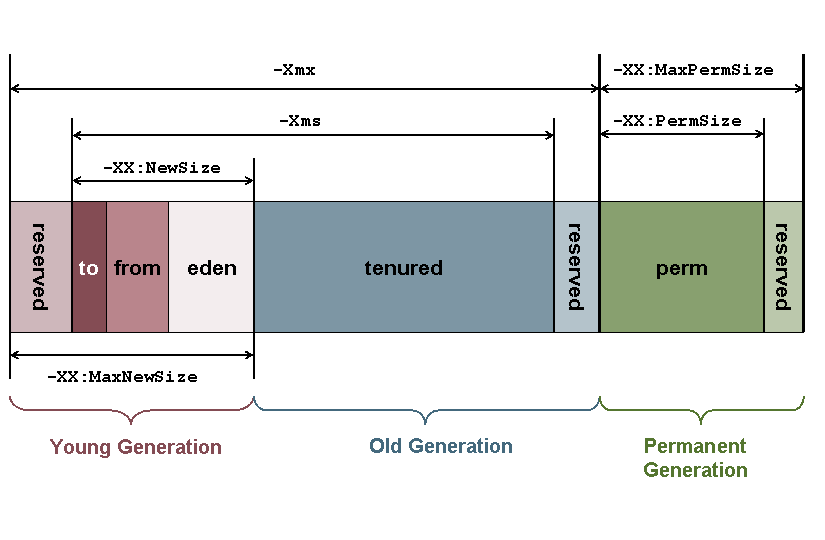
In der Java-Welt gibt es die folgenden beiden Spezifikationen, die sich u.a. damit beschäftigen die Java Memory Architektur zu überwachen können: JSR-174: Monitoring and Management Specification for the Java Virtual Machine und JSR-163: Java Platform Profiling Architecture. JSR-174 definiert Anforderungen an ein JVM Monitoring- und Managementsystem. Der JSR-163 definiert nicht nur Schnittstellen, die von JSR-174 benötigt werden, sondern stellt auch Referenz-Implementierungen und Test-Werkzeuge bereit, um Java-Anwendungen überwachen, fern steuern und messen zu können. Seit JDK5 sind die beiden JSRs in der Laufzeitumgebung integriert (Quelle). Beispiele für eine Schnittstelle und Referenz-Implementierung zur Überwachung der Java Memory Architektur sind die Schnittstelle java.lang.management.MemoryPoolMXBean und die Klasse java.lang.management.MemoryUsage.
Die JVM besitzt eine automatische Speicherverwaltung und benutzt den Heap zum Allokieren von neuen Objekten, der wiederum aus mehreren Speicherbereichen besteht. Außerdem besitzt die JVM den sogenannten Non-Heap Memory in dem sich das sogenannte Method Area befindet, in dem sich die geladenen Klassen befinden. Daraus resultieren mehre Memory Pools. Ein Instanz der Management-Schnittstelle MemoryPoolMXBean repräsentiert also immer einen spezifischen Memory Pool, wie z.B Old Generation oder Eden Space. In Oracle HotSpot Implementierung findet man alle in Abbildung 2 dargestellten Memory Pools wieder. Auf alle Instanzen (sun.management.MemoryPoolImpl) der unterschiedlichen Memory Pools kann man mit der ManagementFactory.getMemoryPoolMXBeans() zugreifen.
Mit der Methode getUsage() bekommt man die geschätzte Speichergröße des aktuellen Memory Pools. Für einen Memory Pool, der vom einem Garbage Collector bereinigt wird, gilt das die Speichergröße sowohl reachable als auch unreachable Objekte beinhaltet.
Die Klasse MemoryUsage beinhaltet die folgenden vier Werte:
| Wert | Beschreibung |
|---|---|
| init | repräsentiert die initiale Speichermenge in bytes, die während des Startvorgangs der JVM allokiert wird. Dieser Wert kann auch undefined sein. |
| used | repräsentiert den aktuellen Speicherverbrauch in bytes. |
| committed | repräsentiert den maximalen Speicherverbrauch, der von der JVM ohne Speicherumstrukturierung garantiert wird. Dieser Wert kann sich über die Laufzeit hinweg ändern. |
| max | repräsentiert maximalen Speicherverbrauch, der von der JVM allokiert werden kann. |
Ähnliche Management-Beans gibt es auch zum Abfragen von anderen Laufzeitmetriken, wie Anzahl an laufenden Threads oder geladenen Klassen. Laufzeitmetriken, die nicht in der java.lang.management API enthalten ist, kann man selbst implementieren. Dazu gibt es die java.lang.instrument API, damit ist es z.B. auch möglich die Laufzeit von Methoden zu messen, in dem man den Bytecode eine Klasse verändert. Dazu verwendet man einen sogenannten Java-Agenten. Diese API ist die Grundlage für viele kommerzielle Profiler und wird üblicherweise als JAR-Datei aufgeliefert. Das folgende Listig zeigt einen Java-Agenten und wie man den Bytecode einer Klasse mit Javassist umschreiben kann, um nach jeden Methoden-Aufruf die Ausführungzeit der Methode in der Konsole ausgegeben wird:
public class AppStashAgent {
public static void premain(String agentArguments, Instrumentation instrumentation) {
instrumentation.addTransformer(new ClassFileTransformer() {
@Override
public byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException {
byte[] result = new byte[0];
try {
String dotClassName = className.replace('/', '.');
ClassPool cp = ClassPool.getDefault();
CtClass ctClazz = cp.get(dotClassName);
for (CtMethod method1 : ctClazz.getDeclaredMethods()) {
method1.addLocalVariable("elapsedTime", CtClass.longType);
method1.insertBefore("elapsedTime = System.nanoTime();");
method1.insertAfter(" { elapsedTime = System.nanoTime() - elapsedTime; "
+ "System.out.println(\" Method elapsedTime = \" + elapsedTime);}");
result = ctClazz.toBytecode();
}
} catch (Throwable e) {
e.printStackTrace();
}
return result;
}
});
}
}
Die meisten Java-Profiler geben zwar einen detaillierten Einblick in eine Anwendung. Es kann aber vorkommen, dass man einen Profiler nicht produktiv Betrieb benutzen kann. Das kann daran liegen, dass dieser Profiler entweder das Java Virtual Machine Profiling Interface (JVMPI) oder das Java Virtual Machine Tool Interface (JVMTI) zum Sammeln von Daten benutzt. Die Verwendung der JVMPI oder JVMTI kann dazu führen, dass sich die Ausführungszeit der Anwendung verlangsamt.
In diesem Fall erzwingt das Vorhandensein eines Agenten, dass der gesamte Bytecode einer Klasse immer von der Festplatte geladen wird, da der Bytecode nach dem Laden der Klasse verändert wird. Um einen solchen Profiler trotzdem benutzen zu können, muss man aufwändig produktionsnahe Lastsenarien mit Lasttest-Werkzeugen wie JMeter oder Gatling simulieren.
Eine Alternative zum klassischen Profiling ist die manuelle Messung der Ausführungszeit im Quellcode, die in eine Logdatei geschrieben wird. Abhängig von der Größe des Entwicklungsteams und Anwendung kann das Schnell zum Wartungsalptraum werden, da man den Quellcode mit dem Messcode verschmutzt. Um den Quellcode nicht zu verschmutzen, existieren Frameworks wie JETM. JETM betrachten wir im Folgenden, um ein besseres Verständnis darüber zu bekommen, welche Möglichkeiten und Konzepte existieren, um eine Anwendung alternativ als mit einem Agenten zu messen.
Java Execution Time Measurement Library (JETM)
Mit Java Execution Time Measurement Library (JETM) kann ein Software Ingenieur die Ausführungsgeschwindigkeit seiner Anwendung bis auf Methoden-Ebene messen. In einer Spring-Anwendungen kann mit JETM die Ausführungsgeschwindigkeit sogar messen werden, ohne eine Zeile Quellcode anzufassen. JETM benutzt dann Spring AOP und generiert dynamische Proxies zum Messen der Spring-Beans. JETM ist sehr einfach zu benutzen, man muss nur die JETM-JARs auf dem ClassPath packen und die Konfiguration der Anwendung entsprechend anpassen. Das folgende Listing zeigt, was man in der web.xml einer Web-Anwendung konfigurieren muss, um mit JETM die einzelnen Requests einer Anwendung zu messen.
<servlet>
<servlet-name>performanceMonitor</servlet-name>
<servlet-class>etm.contrib.integration.spring.web.SpringHttpConsoleServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>performanceMonitor</servlet-name>
<url-pattern>/performance/*</url-pattern>
</servlet-mapping>
<filter>
<filter-name>performance-monitor</filter-name>
<filter-class>
etm.contrib.integration.spring.web.SpringHttpRequestPerformanceFilter
</filter-class>
</filter>
<filter-mapping>
<filter-name>performance-monitor</filter-name>
<url-pattern>*</url-pattern>
</filter-mapping>
Die sogenannte JETM Console macht die Ergebnisse der Messungen verfügbar. In Abbildung 3 ist ein Bildschirmfoto der JETM Konsole zu sehen. Die JETM Console kann man entweder über ein Servlet in eine bestehende Web-Anwenundung integrieren werden oder man benutzt einen Standalone HTTP Console Server. Damit kann JETM sowohl für Macrobenchmarks als auch für Microbenchmarks benutzt werden.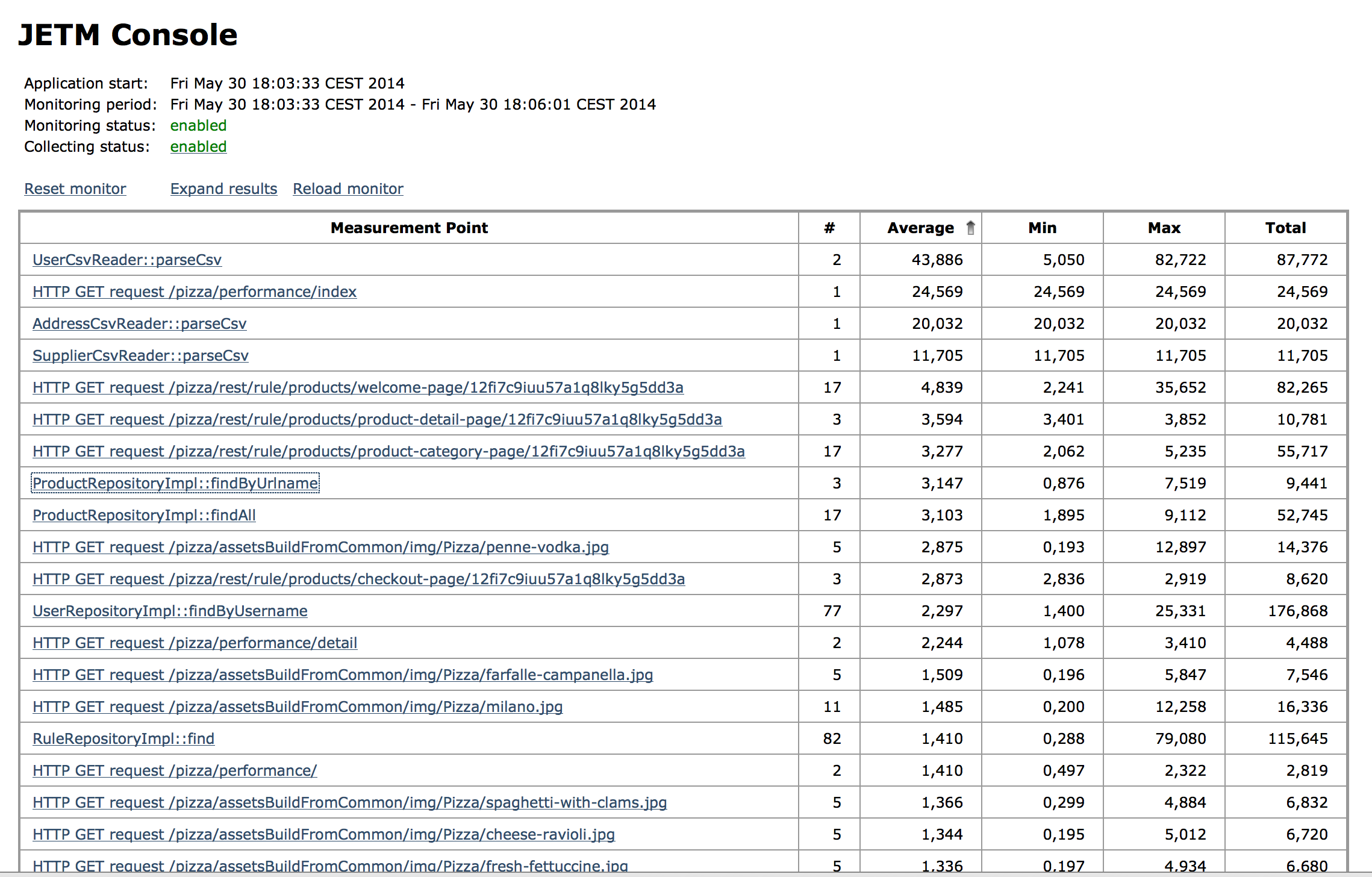
Abbildung 3: JETM Console
Aus den Betrachtungen über die java.lang.management, java.lang.instrument API und JETM ergeben sich noch zwei nicht funktionale Anforderungen an eine Software-Lösung zur Laufzeit-Überwachung einer Java-Anwendung:
- Laufzeitdaten müssen auch in Produktion gesammelt werden können,
- Das Sammeln von Laufzeitmetriken sollte über Konfiguration gestartet werden.
Betrachten wir nun im Folgenden, wie wir aus den definierten funktionalen und nicht-funktionalen Anforderungen ein Minimum Viable Product einer Software-Lösung zur Laufzeit-Überwachung bauen können.
Profiler auf ELK Stack Basis
Wie bereits erwähnt, ergeben sich die folgenden funktionalen und nicht-funktionalen Anforderungen an eine Software-Lösung zur Laufzeit-Überwachung einer Anwendung:
- Laufzeitdaten einer Anwendung sollen kontinuierlich automatisch gesammelt werden,
- Logdaten sollen ebenfalls automatisch kontinuierlich gesammelt werden,
- Laufzeitdaten und Logdaten von mehren Server müssen korreliert werden können,
- Laufzeitdaten müssen auch in Produktion gesammelt werden können,
- Das Sammeln von Laufzeitmetriken sollte über Konfiguration gestartet werden.
Der ELK Stack ermöglicht es Logdaten automatisch zu sammeln und besteht aus den folgenden Komponenten:
- Elasticsearch – für die Suche und Datenanalyse,
- Logstash – zum Zentralisieren, Anreichern und Parsen von Logdaten,
- Kibana – für die Daten Visualisierung.
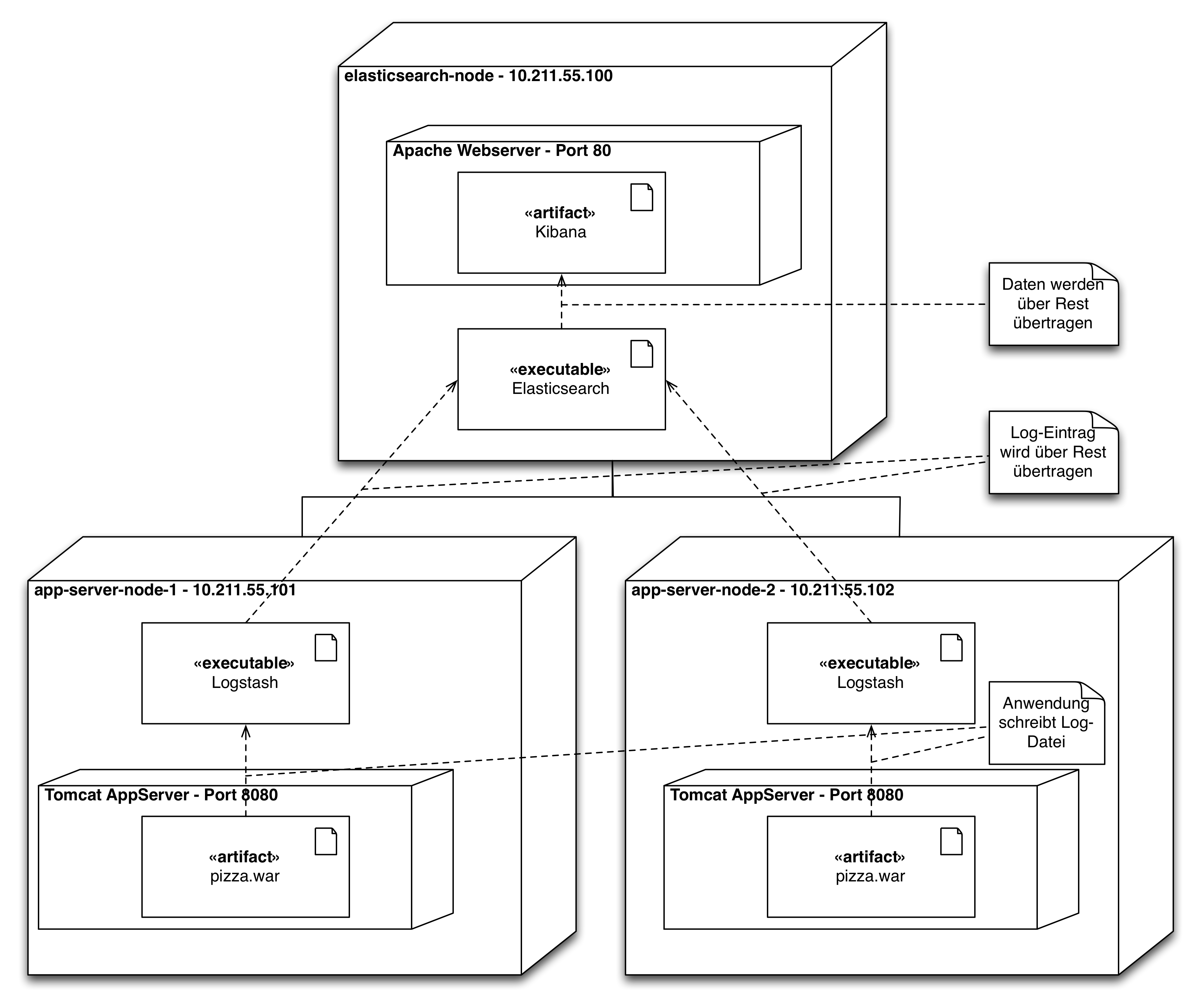
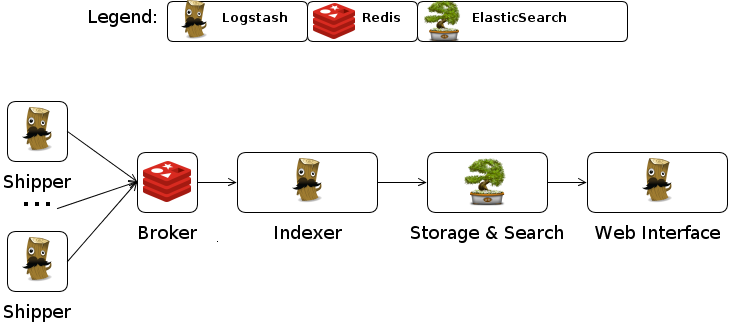
Abbildung 4 zeigt einen möglichen architektonischen Aufbau eines ELK Clusters. Das Cluster besteht aus drei Rechnern. Auf zwei Rechner sind Tomcat-Anwendungserver installiert. Von den Tomcat-Anwendungserver werden kontinuierlich Logdaten schreiben. Auf diesen beiden Rechnern ist deshalb ausserdem Logstash installiert. Logstash wirkt in der Installation als ETL-Tool und extrahiert die Logdaten, transformiert sie ggf., sodass die Logdaten in Elasticsearch geschrieben und von Elasticsearch indexiert werden können. Auf einem dritten Rechner ist ein Apache Webserver installiert, der als Webverzeichnis für Kibana dient, dass die von Logstash gesammelten Logdaten der beiden Tomcat-Anwendungsserver visualisiert. Für die Visualisierung nutzt Kibana die Rest-API von Elasticsearch.
Log = Timestamp + Data
Die Logdaten einer Anwendung bestehen immer aus einem Zeitstempel und irgendwelchen Daten. Die Laufzeitmetriken unserer Anwendung haben einen ähnlichen Aufbau. Zu einem bestimmten Zeitpunkt wird von der Anwendung eine bestimmte Menge des Speichers konsumiert.
Man kann sich die JVM, wie eine echte Maschine vorstellen, die mit Sensoren bestückt ist, diese Sensoren können periodisch zur Überwachung abgefragt werden. Ein solcher Sensor ist z.B. eine MemoryPoolMXBean-Instanz. Wenn man diese Sensordaten in eine Form bringt, die noch über einen Zeitstempel verfügt und in eine Datei schreibt, können die Logdaten von Logstash verarbeitet und in Elasticsearch überführen werden. Das folgende Listing zeigt eine mögliche JSON Struktur für unseren Speichersensor:
{
"name": "PS Old Gen",
"type": "Heap memory",
"@timestamp": "2014-05-28T23:43:19",
"@version": "1",
"init": 266862592,
"used": 2417592,
"committed": 266862592,
"max": 2863661056
}
Damit ist der ELK Stack schonmal in der Lage unsere funktionalen Anforderungen an eine Software-Lösung zur Laufzeit-Überwachung einer Anwendung zu erfüllen. Wir haben aber noch nicht-funktionale Anforderungen definiert, u.a sollen die Laufzeitmetriken auch produktiv gesammelt werden können und das Sammeln über Konfiguration gestartet werden. Um losgelöst von Rest der Anwendung Laufzeitmetriken sammeln, bietet sich ein Runnable an. Ein Runnable kann über den ScheduledThreadPoolExecutor immer im einem Hintergrund der Anwendung laufen und kontinuierlich Laufzeitmetriken sammeln. Denn ScheduledThreadPoolExecutor kann man mit Spring einfach konfigurieren, wie wir später sehen werden. Das folgende Listing zeigt, wie man die MemoryUsage Werte der unterschiedlichen MemoryPoolMXBean in der Konsole im JSON-Format weglassen kann:
public class MemoryLoggingTask implements Runnable {
private static final Logger LOGGER = LoggerFactory.getLogger(MemoryLoggingTask.class);
private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
@Override
public void run() {
for (MemoryPoolMXBean memoryPoolMXBean : ManagementFactory.getMemoryPoolMXBeans()) {
try {
String message = memoryUsageAsJsonString(memoryPoolMXBean);
LOGGER.info(message);
} catch (IOException e) {
LOGGER.error("Object could not converted to JSON String:", e);
}
}
}
private String memoryUsageAsJsonString(MemoryPoolMXBean memoryPoolMXBean) throws IOException {
return OBJECT_MAPPER.writeValueAsString(buildMemoryUsageInfo(memoryPoolMXBean));
}
private MemoryUsageInfo buildMemoryUsageInfo(MemoryPoolMXBean memoryPoolMXBean) {
return MemoryUsageInfo.builder()
.name(memoryPoolMXBean.getName())
.type(memoryPoolMXBean.getType().toString())
.usage(memoryPoolMXBean.getUsage())
.build();
}
}
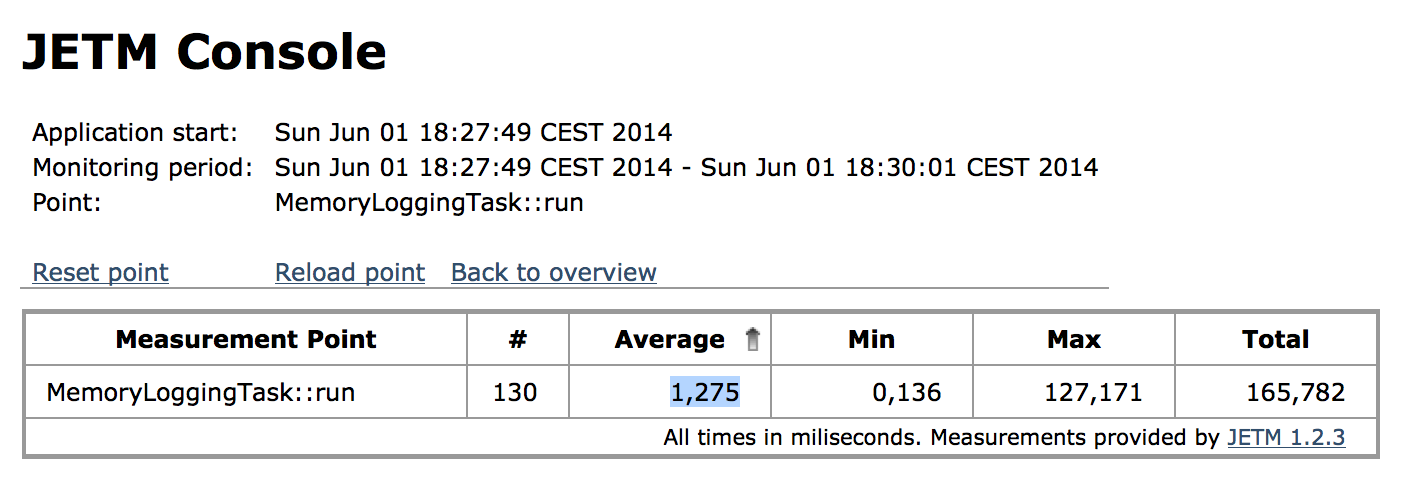
Die Frage ist nun: Ist unser MemoryLoggingTask schnell genug für den produktiven Einsatz? Abbildung 5 zeigt einen Microbenchmark der run-Methode, der mit JETM aufgezeichnet wurden ist. Die Methode wurde 130 mal aufgerufen und die Ausführungszeit braucht im Mittel 1ms. Was man in der Abbildung nicht sieht, ist das der Maximalwert bei ersten Aufruf erfolgt ist. Bei jeden weiteren Methoden wird ungefähr 150ns für die Ausführung benötigt. Damit spricht nichts gegen den produktiven Einsatz des MemoryLoggingTask.
Die letzte nicht-funktionale Anforderung ist, dass das Sammeln von Laufzeitmetriken über Konfiguration gestartet werden sollte. Wie schon erwähnt, ist es mit Spring sehr einfach unseren MemoryLoggingTask im Hintergrund laufen zulassen. Das folgende Listing zeigt, was man dazu machen muss.
<bean id="appStashMemoryLogging" class="io.github.appstash.task.MemoryLoggingTask" />
<task:scheduled-tasks scheduler="appStashScheduler">
<task:scheduled ref="appStashMemoryLogging" method="run" fixed-delay="1000"/>
</task:scheduled-tasks>
<task:scheduler id="appStashScheduler" pool-size="10"/>
Zusammenfassung
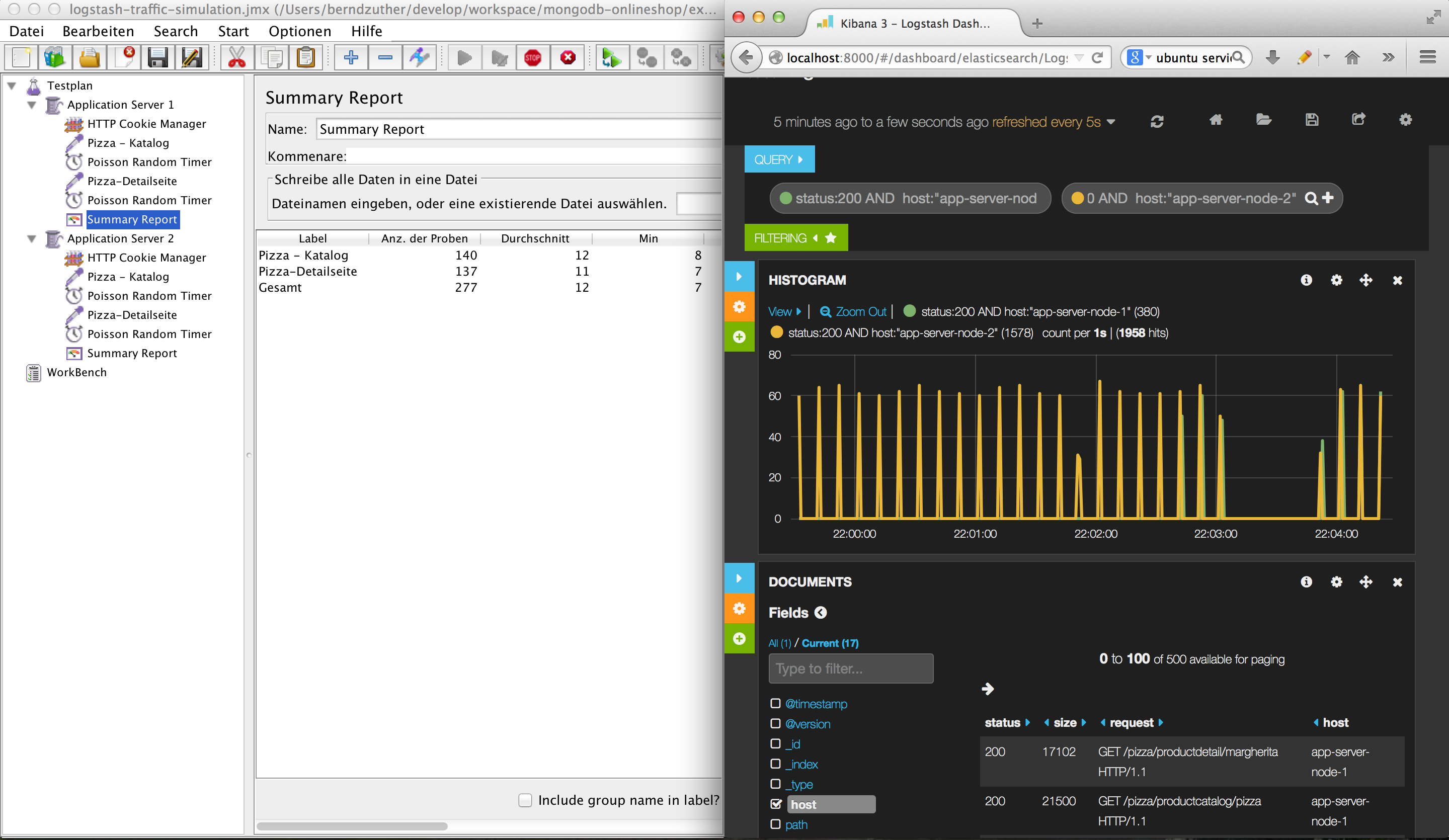
Wie haben in diesen Beitrag gesehen, dass man sich mit einfachsten Mitteln einen Profiler selber schreiben kann. Da Laufzeitmetriken auch als Zeitstempel mit Daten gesehen werden können, kann man diese Daten in eine Datei schreiben und mit einem Loganalysewerkzeug visualisieren. Abbildung 6 zeigt die Kibana Visualisierung vom Heap-Speicher neben VisualVM. Deutlich zu erkennen ist die kontinuierliche Garage Collection des Heaps. Natürlich kann man das gleiche Konzept auch mit anderen Loganalysewerkzeugen, wie z.B. Splunk nutzen, um ähnliche Visualisierungen herzustellen.
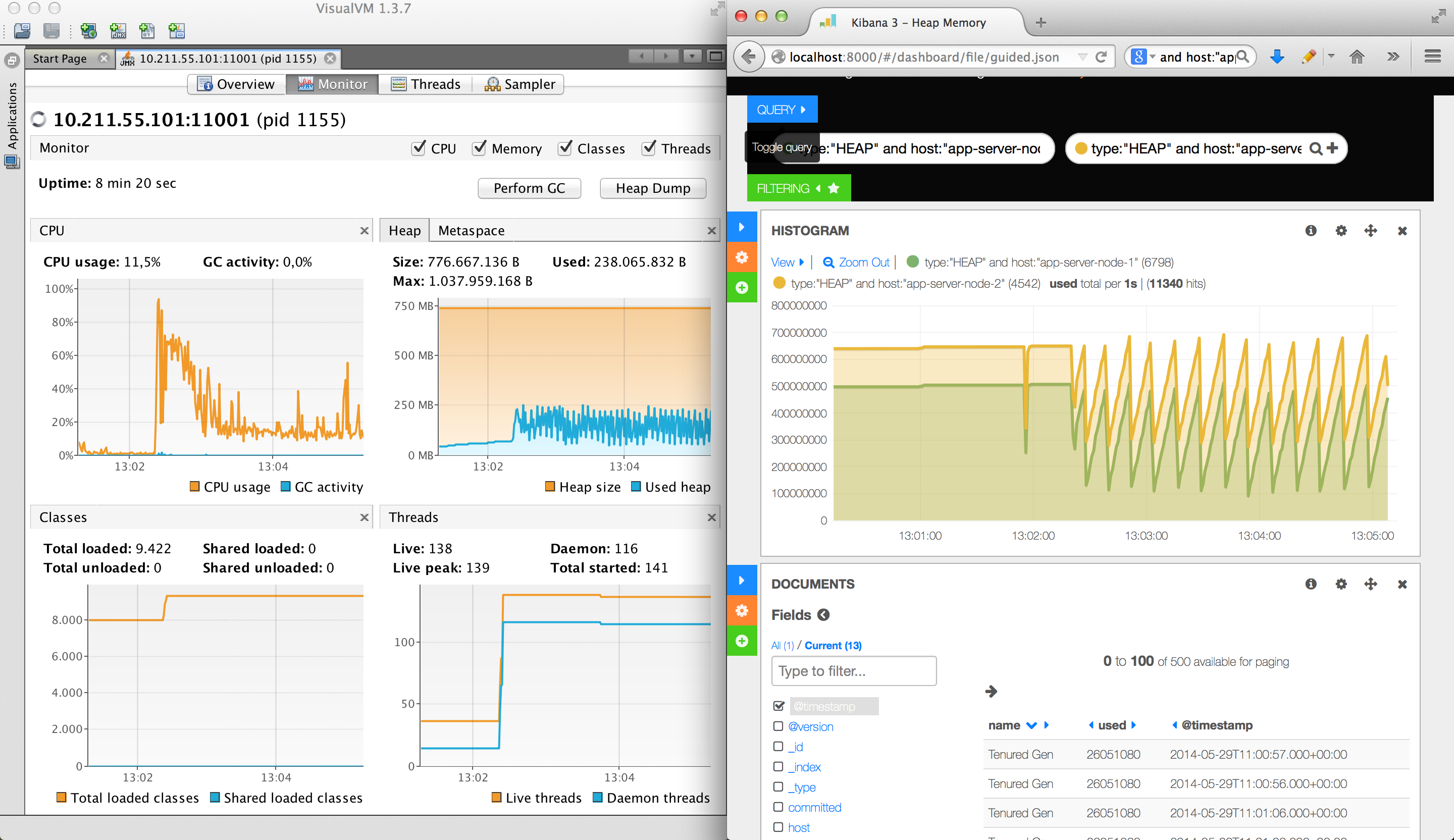
Um den kompletten Cluster, der in Abbildung 4 dargestellt ist, zu starten, muss man nur VirtualBox und Vagrant installieren. Danach kann man nur die folgenden drei Befehle ausführen. Das in Abbildung 6 dargestellte Dashbord befindet sich unter /appstash/external/Heap Memory Dashboard.
bernd@mbp ~$ git clone https://github.com/zutherb/AppStash.git appstash bernd@mbp ~$ git checkout elk-example bernd@mbp ~$ cd appstash/vagrant bernd@mbp ~$ vagrant up
Auf die inAbbildung 4 im dargestellten Komponenten des ELK Stacks kann man über die folgenden Port Forwardings zu greifen:
- Kibana – http://localhost:8000/
- Elasticsearch – http://localhost:9200/
- Applikation 1 – http://localhost:8080/pizza/
- Applikation 2 – http://localhost:8081/pizza/