
Softwareentwicklung wandelt sich, anstatt Software für die nächsten Jahre zu planen, zu entwickeln und dann erst dem Kunden zu präsentieren, arbeiten Fachabteilungen oft mit kleinen Hypothesen. Diese Hypothesen werden mithilfe von A/B Tests direkt am Kunden validiert und kommen dann als neue Userstories in den Entwicklungsprozess. Damit werden schrittweise Unternehmensprozesse und bestehende Software optimiert. Durch dieses Vorgehen bauen Fachabteilung Software, die ihre Kunden wirklich wollen. Das stellt die IT-Abteilungen natürlich vor die Herausforderung öfter und schneller ausliefern zu müssen, um schneller von den Testergebnissen profitieren zu können und letztlich mehr Umsatz zu generieren.
Beispielsweise kann eine simple Änderung der Farbe eines Links in einem Online-Shop eine Konvertierungssteigerung von 20% auslösen. Ein solche Änderung ist relativ schnell umgesetzt, doch selbst mit Continuous Delivery und einer Deployment Pipeline kann, der Durchlauf bis in Produktion mehrere Stunden in Anspruch nehmen, was ziemlich viel Geld kosten kann. Es gibt deshalb Stimmen, die meinen, dass solche langen Durchlaufzeiten am architektonischen Aufbau der Anwendungen liegt.
Aufbau von Web-Anwendungen
Web-Anwendungen sind häufig aus den folgenden drei Teilen aufgebaut:
- Einer Benutzerschnittstelle (z.B. HTML),
- einer Datenbank und
- einer Server-Komponente.
Die Server-Komponente kümmert sich um die Abarbeitung der HTTP Requests, führt die Domänenlogik aus, ließt und schreibt Daten aus/in die Datenbank, bestimmt welche Teile der Benutzerschnittstelle ausgeliefert werden müssen. Jede Änderung in diesem System erfordert einen Build und ein Deployment einer neuen Version der kompletten Software. Solche Anwendungen werden auch Monolithen genannt.
Auch wenn Monolithen sehr erfolgreich sein können, gibt es eine steigende Anzahl von Leuten, die mit diesen Ansatz nicht zufrieden sind, weil man auch für kleine Änderungen sehr hohe Durchlaufzeiten bis in Produktion hat und die Entwicklungsteams nicht mehr richtig skalieren, da man immer wieder die komplexen und zeitaufwendigen Buildprozesse der Monolithen durchlaufen muss und Änderungen an der Software immer schwieriger werden. Außerdem skalieren Monolithen schlecht. Wenn man einen solchen Monolithen skalieren möchte, muss man immer die komplette Anwendung verteilen, auch wenn nur bestimmte Teile der Anwendung Performance-Probleme hervorrufen.
Es gibt Stimmen, die meinen, dass die klassische Drei-Schichten nicht mehr gut genug skaliert, um kleine gewinnbringende Features schnell genug ausliefern zu können. Deshalb erfreut sich das Konzept der Microservice-Architektur immer größer Beliebtheit. Ziel ist es die Anwendung entsprechend ihrer Fachlichkeit zuzuschneiden und in kleine Services zu unterteilen, die getrennt von einander ausgeliefert werden können. Damit soll die Durchlauf eines Features bis in Produktion verringert werden.
Die Microservice-Architektur zerschneidet Anwendungen in eine Anzahl an Diensten. Diese Dienste sind eigenständig deploy- und skalierbar. Jeder Dienst stell eine abgrenzte Fachlichkeit bereit, kann in einer beliebigen Programmiersprache implementiert sein und von unterschiedlichen Teams bereitgestellt werden. Zerschneidet man eine Software in eigenständige Dienste erzeugt man natürlich eine Vielzahl an Deployment-Artifakten. Häufig hat der Betrieb aber schon Probleme mit dem Deployment einer einzelnen monolithischen Anwendung. Deshalb muss man einen Weg finden Abhängigkeiten besser aufzulösen, die für eine erfolgreiche Auslieferung benötigt werden.
Deployment von Web-Anwendungen
In der Regel werden Web-Anwendungen in einen Anwendungsserver aufgeliefert. Ein Anwendungsserver stellt einen Container dar, der spezielle Dienste zur Verfügung stellt, wie beispielsweise Transaktionen, Authentifizierung oder den Zugriff auf Verzeichnisdienste, Webservices und Datenbanken über definierte Schnittstellen.
Um das Deployment in einem Anwendungsserver zu standardisieren gibt es das Web Archive oder das Enterprise Archive. Ein Web Archive ist ein Dateiformat, das beschreibt, wie eine vollständige Webanwendung nach der Java-Servlet-Spezifikation in eine Datei im JAR- bzw. ZIP-Format verpackt wird. Bei einem Enterprise Archive handelt es sich ebenfalls um eine Datei im JAR- bzw. ZIP-Format, die ein vollständiges Anwendungsprogramm – meist eine Webanwendung – gemäß dem Standard Java Platform, Enterprise Edition (Java EE) enthält. Leider reichen diese beiden Standards nicht aus, um alle Abhängigkeiten aufzulösen, die eine Anwendung für den fehlerfreien Betrieb benötigen.
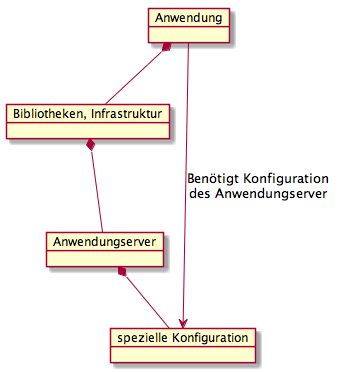
Die Abbildung zeigt die Abhängigkeiten zwischen Anwendung und Anwendungsserver. Eine Anwendung hängt vom Anwendungsserver ab, da die Anwendung Bibliotheken und Infrastruktur des Anwendungsserver nutzt. Umgekehrt ist der Anwendungsserver aber auch von der Anwendung abhängig, da der Anwendungsserver für eine Anwendung speziell konfiguriert werden muss. Damit ist ein Anwendungsserver eigentlich Teil einer Anwendung und man sollte Anwendungsserver und Anwendung als eine Komponente sehen.
Benötigt eine neue Version der Anwendung auch einen neue Version des Anwendungsserver gibt es für den Betrieb häufig viele manuelle Schritte auszuführen, weil diese Abhängigkeiten in eine WAR oder einem EAR nicht ausgedrückt werden können. Diese Abhängigkeiten werden dann oft textuell in Form eines Tickets beschrieben und wenn man Glück hat werden die Instruktionen vom Betrieb richtig ausgeführt. Ähnliches gilt bei Datenbankänderungen. Es wäre deshalb wünschenswert Deployment-Artifakte zu haben, die auch diese Abhängigkeiten ausdrücken können. Ein Beispiel für solche Deployment-Artifakte liefert Apple.
Deployment von Anwendungen über den App Store
 Apple liefert pro Sekunde mehr als 800 Apps über den App Store aus (Quelle). Apple-typisch lädt man sich eine Anwendung herunter und nach einem Klick auf das Icon läuft die Anwendung immer sofort, ohne das der Benutzer noch irgend etwas machen muss.
Apple liefert pro Sekunde mehr als 800 Apps über den App Store aus (Quelle). Apple-typisch lädt man sich eine Anwendung herunter und nach einem Klick auf das Icon läuft die Anwendung immer sofort, ohne das der Benutzer noch irgend etwas machen muss.
Apple löst die Herausforderung eine Anwendung auszuliefern mit dem sogenannten Application Bundle. Native Mac OS X Applikationen sind mehr als nur eine einfache ausführbare Datei, auch wenn ein Benutzer im Finder immer nur ein einzelnes Ic on sieht. Unter Mac OS X besteht eine Applikation Bundle aus einer Verzeichnisstruktur, die sowohl die ausführbaren Dateien als auch alle benötigen Ressourcen enthält, die von einer Applikation benötigt werden. Diese Struktur ist von Apple genau definiert.
on sieht. Unter Mac OS X besteht eine Applikation Bundle aus einer Verzeichnisstruktur, die sowohl die ausführbaren Dateien als auch alle benötigen Ressourcen enthält, die von einer Applikation benötigt werden. Diese Struktur ist von Apple genau definiert.
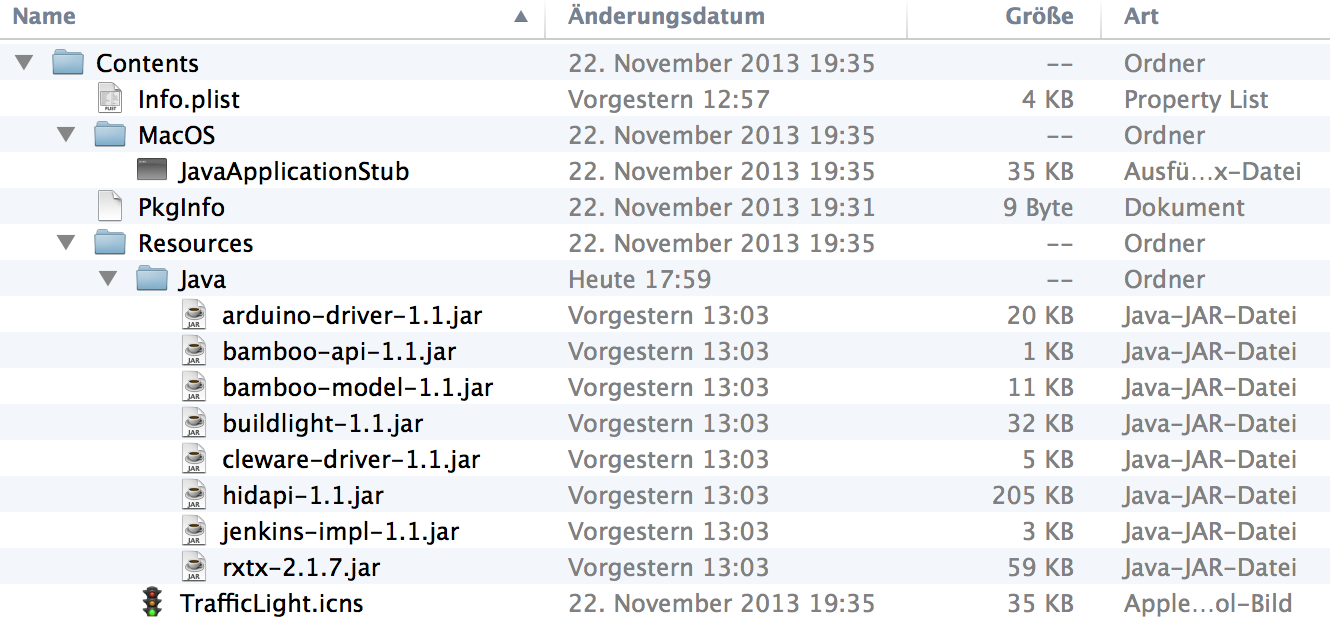
Ein Application Bundle enthält die folgenden Verzeichnisse und Dateien:
- Eine Info.plist Datei im Contents Verzeichnis, die wichtige Meta-Informationen enthält, die von Mac OS X benutzt werden, um die Anwendung zu starten. (“Java Dictionary Info.plist Keys”)
- Außerdem sollte eine Datei mit dem Namen PkgInfo in dem Contents Verzeichnis enthalten sein. (“Data Type Registration”)
- Die Icons, die im Dock und im Finder angezeigt werden, befinden sich im Resources Verzeichnis.
- Im Resources Verzeichnis werden außerdem Dateien abgelegt, die für die Ausführung benötigt werden.
- Im MacOS Verzeichnis befinden sich die ausführbaren Dateien.
Wenn man eine Anwendung im App Store veröffentlichen möchte, müssen alle Ressourcen, die von der Anwendung benötigt werden mit der Anwendung ausgeliefert werden. Ansonsten wird die Anwendung von Apple abgelehnt und kann nicht veröffentlich werden. Dieses Konzept scheint sich wunderbar zu eignen um einen Microservice auszuliefern. Meistens hat man in Produktion aber keine Apple Server. Deshalb wäre es wünschenswert ein alternativ Konzept dafür zu haben. Häufig werden Webanwendungen auf einen Linux-Server ausgeliefert. Daher hat die Anwendung noch eine zusätzliche Abhängigkeit zu Infrastruktur und diese Abhängigkeit kann man benutzen, um die Anwendung auszuliefern.
Linux-Paketverwaltung
Die meisten Linux Distributionen verfügen über eine Software-Paketverwaltung. Eine Software-Paketverwaltung ermöglicht die komfortable Verwaltung von Software, die in Paketform vorliegt. Dazu gehören das Installieren, Aktualisieren und Deinstallieren der Software.
Voraussetzung für Paket-Management ist, dass die zu installierende Software als entsprechendes Paket vorliegt. Ein solches Paket wird meistens von einem Betriebssystemanbieter erstellt, angeboten und gepflegt. Software wird meistens verteilt in unterschiedlichen Verzeichnissen des System installiert. Diese Verzeichnisse sind im Filesystem Hierarchy Standard definiert.
Änderungen, welche die Paketverwaltung zur Installation des Pakets am System vornehmen muss, werden von der Paketverwaltung aus dem Paket ausgelesen und umgesetzt. Erkennt die Paketverwaltung dabei, dass noch weitere Software für das Funktionieren benötigt wird (sogenannte Abhängigkeit, z. B. eine Programmbibliothek), aber noch nicht installiert ist, warnt sie entweder oder versucht, die fehlende Software mit den ihr zur Verfügung stehenden Mitteln, z. B. aus einem Repository, nachzuladen und vorweg zu installieren.
Konkrete Beispiele für Programme um Software-Pakete zu installieren sind:
- Das Programm RPM, dass Pakete vom Typ *.rpm installieren und löschen kann und
- das Programm Dpkg, dass Pakete vom Typ *.deb installieren und löschen kann.
Beide können aber keine Abhängigkeiten auflösen, da sie keine Funktionen haben, um Software nachzuladen. Dies können höhere Schichten der Paketverwaltungen wie YUM, APT, pkg-get und andere. Mit YUM oder APT ist es aber somit möglich auch die Abhängigkeiten zwischen Anwendungsserver und Anwendung aus zu drücken. Da ich häufig Ubuntu verwende und ich deshalb mit Deb-Paketen besser vertraut bin, möchte ich diese im folgenden Besprechen. Die Konzepte für Rpm-Pakete sind allerdings ähnlich.
Aufbau ein Deb-Paket
Jedes Deb-Paket besteht aus drei Dateien, die mittels des UNIX-Kommandos ar oder dem debianspezifischen Kommando dpkg-deb entpackt werden können:
- debian-binary: eine Textdatei mit der Versionsnummer des verwendeten Paketformats.
- control.tar.gz: ein gepacktes Archiv, dass Dateien enthält, die zur Installation dienen oder Abhängigkeiten auflisten. Hier werden nur ein paar Beispiele aufgeführt. Weiterführende Beschreibungen dazu finden sich z. B. in der Offiziellen Debian FAQ zu .deb Paketen.
- control enthält eine Kurzbeschreibung des Paketes sowie weitere Informationen, wie dessen Abhängigkeiten.
- md5sums enthält MD5-Prüfsummen aller im Paket enthaltenen Dateien, um Verfälschungen erkennen zu können.
- conffiles listet die Dateien des Paketes auf, die als Konfigurationsdateien behandelt werden sollen.
- preinst, postinst, prerm, postrm sind optionale Skripte, die vor oder nach dem Installieren, Aktualisieren oder Entfernen des Pakets ausgeführt werden. Sie werden mit den Rechten des Nutzers root ausgeführt.
- data.* Ist ein mit komprimiertes Archiv und enthält die eigentlichen Programmdaten mit relativen, beim Stammverzeichnis beginnenden Pfaden.
Integration in das Buildsystem
Mit jdeb gibt es eine Bibliothek, die einen Ant task und ein Maven Plugin bereitstellt um Debian Pakete zu erstellen. Diese Bibliothek ist Plattform unabhängig und baut Debian Pakete ohne die Installation von irgendwelchen zusätzlichen Tools.
Natürlich gibt es auch ein Gradle-Plugin das Debian Pakete baut. Das Plugin basiert auch auf jdeb und stellt eine Brücke zwischen jdeb und Gradle dar. Das folgende Listing zeigt die Verwendung des Plugins zusammen mit dem Application Plugin:
apply plugin: 'application'
apply plugin: 'pkg-debian'
debian {
packagename = "product"
publications = ['mavenStuff']
controlDirectory = "${projectDir}/debian/control"
changelogFile = "${projectDir}/debian/changelog"
outputFile = "${buildDir}/debian/${packagename}_${version}.deb"
data {
dir {
name = "${projectDir}/debian/data"
exclusions = ["**/.DS_Store", "changelog"]
}
dir {
name = "${buildDir}/debian-data/"
exclusions = ["**/.DS_Store"]
}
file {
name = "${projectDir}/src/main/resources/application.conf"
target = "etc/product/application.conf"
mapper {
fileMode = "755"
}
}
}
}
task prepareDeb {
dependsOn installApp
copy {
from "${buildDir}/install/"
into "${buildDir}/debian-data/usr/share/"
}
}
Zusammenfassung
Die Microservices-Bewegung erscheint auf den ersten Blick, wie das reaktive Manifest der Fachabteilung. Durch das parallele Bearbeiten von Fachlichkeiten kann das vorher monolithische Deployment von Anwendungen parallelisiert werden und die IT Abteilung schneller liefern. Dadurch erzeugt man aber eine Vielzahl an Deployment-Artifakten, die gemanagt werden müssen. Häufig ist ein monolithisches Deployment aber schon schwer genug. Da sehr viele Abhängigkeiten existieren. Sehr oft werden Anwendungen auf Linuxsystemen ausgeliefert. Diese Abhängigkeit zur Infrastruktur kann man aber auch ausnutzen, in dem man die Paketverwaltung der Linuxsysteme nutzt, um die Anwendungen auszuliefern, man baut dann nicht einfach nur ein Web Archive (WAR Dateien), sondern liefert ein Linux-Paket aus, darin ist alles enthalten, was ein Dienst benötigt, um ordnungsgemäß ausgeführt werden zu können. Die Paketverwaltung löst dann alle Abhängigkeiten auf, damit eine Anwendung/Dienst läuft und führt alle nötigen Schritte zur Installation der Software automatisiert aus. Damit erhält man auf den Linuxsystemen ein Apple ähnliches Deployment und kann sich eine Art App Store in Form eines Repository aufbauen, das die Auslieferung von Software stark vereinfach. Theoretisch ist durch dieses Vorgehen möglich seinen kompletten IT-Stack einfach nur mit einen Befehl auszuliefern , führt man z.B. „apt-get upgrade“ aus, werden alle Pakete wenn möglich auf verbesserte Version aktualisiert.
